Jak víte, počítač ukládá informace v binární formě a reprezentuje je jako posloupnost jednotek a nul. Chcete-li převést informace do formy, která je vhodná pro lidské vnímání, každá jedinečná posloupnost číslic, která je zobrazena, je nahrazena odpovídajícím znakem. Jedním z korelačních systémů pro binární kódy s tiskovými a řídícími znaky je kódování ASCII. Na dnešní úrovni vývoje počítačové techniky od uživatele nevyžaduje znalost kódu každého konkrétního znaku. Obecné pochopení způsobu kódování je však velmi užitečné a pro některé kategorie odborníků je to naprosto nezbytné.
Vytvoření ASCII
Původní kódování bylo vytvořeno v roce 1963 a poté aktualizováno již 25 let. V původní verzi obsahovala tabulka znaků ASCII 128 znaků, později se objevila rozšířená verze, kde byly uloženy prvních 128 znaků a kódy s aplikovaným 8. bitem odpovídají dříve nezadaným znakům.
Po mnoho let bylo toto kódování nejoblíbenějším na světě. V roce 2006 převzal vedení latiny 1252 a od konce roku 2007 je Unicode vedoucím postavením.
ASCII podání počítače
Každý znak ASCII má svůj vlastní kód sestávající z 8 znaků, představující nula nebo jednotku. Minimální počet v této reprezentaci je nula (osm nul v binárním systému), což je kód prvního prvku v tabulce.
Maximálníbinární kód ve verzích Výchozí ASCII jsou nula + sedm jednotek, a v rozšířené verzi - osm jednotek, které jsou propojeny jako osmý bit.
Řídicí obrázky
kontrolní znaky tzv znaky bez grafické znázornění slouží k uspořádání textu, správu zařízení, a tak dále. D. mohou znamenat počátek nebo konec textu, kartách, generování zvuku, různé operace pro telex (TTY - data stroje na elektrické kanálu) rozlišení výstupního zařízení, vrátit zpět a další
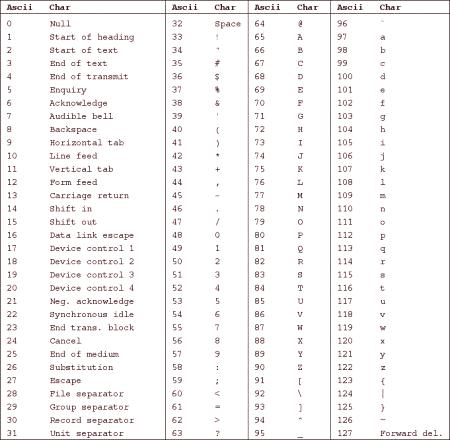
V tabulce znaků ASCII jsou pod řídicími znaky přidělena pozice od 0 do 31 a 127. Celkem 33 značek
Ostatní znaky
Zbývající 95 pozice vyhrazené pro interpunkčních znamének a matematických operací, desetinná místa, písmena abecedy, různé rejstříku: „A“ a velký „a“ horizontální kódy odpovídají různým tabulky symbolů ASCII
Čísla znaků v tabulce
Pokud osoba vyvíjí software nebo provádí jiné úkoly v oblasti informačních technologií, potřebuje znát čísla řady znaků ASCII. Jak bylo uvedeno výše, pozice 0-31 a 127 zaujímají kontrolní symboly. Číslo 32 je přiřazeno mezerou, čísla 33-47 a 58-64 jsou přiřazena interpunkci a základním matematickým operacím.
Latinská písmena jsou uspořádána abecedně a mají čísla od 65. do 90. let. Řádky jsou také uspořádány abecedně, jejich pozice - od 97 do 122. Zbývající čísla (91-96 a 123-126) jsou upevněny na čtvercových a kudrnatých závorkách,šikmou a přímou čáru, stejně jako některé diakritické značky. Kompletní tabulka symbolů v praktické grafické reprezentaci lze vidět na obrázku výše. Níže uvedený obrázek ukazuje počet znaků v ruské tabulce znaků ASCII.
Rozšíření ASCII
Vzhledem k tomu, originální verze vyvinutého kódováním na americkém uživatele, tam nebyly poskytnuty nejen různé druhy psaní a abecedy národní, a dokonce i snadné používat diakritická znaménka upotreblyayuschyhsya aktivně v evropských jazycích.
Pro generování rozšířeného kódování byl použit 8. bit. Tato verze obsahuje symboly národní i evropské abecedy fonetickým přepisem grafických prvků použitých pro kreslení tabulky, množství matematických symbolů. Některé znaky ASCII se dnes používají jen zřídka. To se týká především značky zaměstnanců kreslení tabulky, jako v předchozích letech, protože rozvoj posílené kódování implementovány mnohem pohodlnější způsoby, jak grafickou reprezentaci tabulek.
Národní varianty kódování
předtím rozšířené možnosti ASCII zobrazit národních abeced používají recyklovaný kódování verze, kde místo písmen které ruské, řecké, arabské znaky. Dva kódy v tabulce byly nastaveny tak, aby přepínaly mezi standardním US-ASCII a jeho národní variantou.
Po začátku ASCII nebyly zahrnuty 128 a 256 znaků, distribuce se stala volboukódování, ve kterém byla původní verze tabulky uložena v prvních 128 kódech s nulovým 8bitovým. Znaky národního písma byly uloženy v horní polovině tabulky (128-255). Nepotřebujete znát ASCII znakové kódy přímo. Vývojář softwaru obvykle postačuje k tomu, aby poznal číslo položky v tabulce, aby v případě potřeby vypočítal kód pomocí binárního systému.
Ruský jazyk
Po vývoji kódování pro skandinávské jazyky, čínštinu, korejštinu, řečtině apod. Se Sovětský svaz ujal vlastní verze. Brzy se 8bitový variant kódování nazvaný KOI8 uchoval první 128 znaků kódů ASCII a přidělil stejné pozice pro písmena národní abecedy a další znaky. Implementace Unicode KOI8 dominovala ruskému segmentu internetu. Existovaly varianty kódování pro ruské i ukrajinské abecedy.
Otázky ASCII
Vzhledem k tomu, že počet prvků dokonce ani v rozšířené tabulce nepřekročil hodnotu 256, chyběla možnost umísťování několika různých skriptů do jednoho kódování. V 90. letech se zdálo, že Runet má problém s "krocozyabrem", když texty napsané ruskými znaky ASCII nebyly správně zobrazeny. Problémem bylo nesoulad kódů různých variant ASCII mezi sebou. Připomeňme si, že pozice 128-255 mohou mít různé značky a při změně jednoho cyrilského kódování na jiný, všechny písmena textu byly nahrazeny jinými písmeny, které mají identické číslo v jinémkódování verzí.
Současný stav
S nástupem Unicode popularita ASCII prudce klesla. Důvodem je skutečnost, že nové kódování umožnilo umístit znaky téměř všech psaných jazyků. V tomto případě odpovídají prvních 128 znaků ASCII stejným znakům v kódování Unicode.
V roce 2000 bylo ASCII nejoblíbenějším kódováním na internetu a bylo použito 60% indexovaných webových stránek Google. Do roku 2012 se podíl těchto stránek snížil na 17%, zatímco Unicode (UTF-8) se stal nejoblíbenějším zdrojem kódování. ASCII je tedy důležitou součástí historie informačních technologií, ale její využití v budoucnu se zdá být neproporcionální.