Kódování zvuku se týká způsobů ukládání a přenosu zvukových dat. Následující článek popisuje způsob práce těchto kódování. Všimněte si, že toto je poměrně složité téma - "Hloubka kódování zvuku". Definice této koncepce bude také uvedena v našem článku. Pojmy uvedené v článku jsou určeny pouze k obecnému přezkumu. Rozšiřujeme pojem hloubky kódování zvuku. Některé z těchto odkazů mohou být užitečné pro pochopení toho, jak API funguje a jak artikulovat a zpracovávat zvuk ve vašich aplikacích.
Jak najít hloubku kódování zvuku
Audio formát není ekvivalentní kódování zvuku. Například populární formát souboru, jako je WAV, definuje formát hlavičky zvukového souboru, ale sám o sobě není kódování zvuku. WAV soubory často, ale ne vždy používají lineární PCM kódování. Na druhou stranu FLAC je formát souboru a kódování, což někdy vede ke zmatku. V rozhraní Speech API FLAC je hloubka kódování zvuku jediným kódováním, které vyžaduje, aby audio data obsahovala záhlaví. Všechno ostatní kódování označuje tichá zvuková data. Když odkazujeme na rozhraní FLAC ve rozhraní API řeči, vždy se odkazujeme na kodek. Když odkazujeme na formát souboru FLAC, použijeme formát .FLAC.
Není nutné zadávat kódování a vzorkovací frekvenci pro soubory WAV nebo FLAC. Je-li tato možnost vynechána, rozhraní API založené na cloudu automaticky určuje kódování a vzorkovací frekvenci souborů WAV nebo FLAC na základě záhlaví souboru.Pokud zadáte hodnotu pro kódování nebo vzorkovací frekvenci, která neodpovídá hodnotě v záhlaví souboru API jazyka cloud, vrátí se chyba.
Jaká je hloubka kódování zvuku?
Zvuk sestává z oscilogramů skládajících se z interpolace vln různých frekvencí a amplitud. Chcete-li reprezentovat tyto formy signálů v digitálním prostředí, musí být signály odmítnuty rychlostí, která může představovat zvuky nejvyšší frekvence, kterou chcete hrát. Pro ně je také nutné udržovat dostatečnou hloubku bitů, aby reprezentovaly oscilogramy správné amplitudy (objem a měkkost) založené na zvukovém vzorku. Schopnost reprodukovat reprocesaci frekvencí je známá jako její frekvenční odezva a schopnost vytvářet správný objem a měkkost je známá jako dynamický rozsah. Společně jsou tyto termíny často označovány jako spolehlivost zvukového zařízení. Hloubka kódování zvuku je prostředkem, kterým můžete obnovit zvuk pomocí těchto dvou základních principů, stejně jako schopnost efektivně ukládat a přenášet takové údaje.
Frekvence odběru vzorků
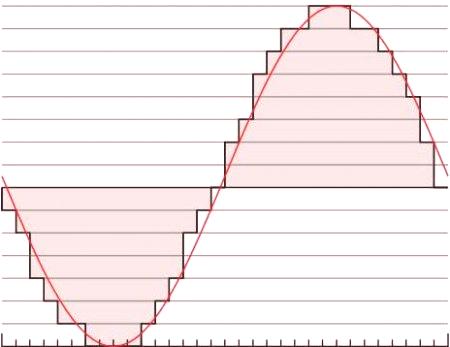
Zvukový signál existuje jako analogový průběh. Segment digitálního zvuku se blíží této analogové vlně a sampluje její amplitudu poměrně vysokou rychlostí, aby simuloval vlastní vlnové frekvence. Vzorkovací frekvence digitálního zvuku určuje počet vzorků odebraných z audio výstupu (v sekundách). Vysoká vzorkovací frekvence zvyšuje schopnost digitálního zvuku přesně reprezentovat vysoké frekvence.
V důsledku větyNyquist-Shannon, obvykle musíte vyzkoušet alespoň dvojnásobek frekvence jakékoliv zvukové vlny, která musí být digitálně zaznamenána. Například pro reprezentaci zvuku v dosahu lidského sluchu (20-20000 Hz) by se digitální zvuk měl zobrazit nejméně 40 000krát za sekundu (což je důvod, proč zvuk CD používá vzorkovací frekvenci 44100 Hz).
Hloubka Beat
Hloubka kódování zvuku je účinek na dynamický rozsah daného zvukového vzorku. Vyšší bitová hloubka umožňuje zobrazit přesnější amplitudy. Pokud máte ve stejném zvukovém vzorku hodně hlasitých a měkkých zvuků, budete potřebovat více bitů, aby správně vysílali tyto zvuky. Vyšší bitové hloubky také snižují poměr signál /šum v zvukových vzorcích. Pokud je hloubka kódování zvuku 16 bitů, hudební zvuk disku CD se přenáší pomocí těchto hodnot. Některé metody komprese mohou kompenzovat nižší bitové hloubky, ale jsou obvykle ztrátové. DVD Audio používá 24 bitů hloubky, zatímco většina telefonů má hloubku kódování zvuku 8 bitů.
Zvuk bez zvuku
Velké množství digitálního zpracování zvuku používá tyto dvě metody (vzorkovací frekvence a bitová hloubka) pro snadné ukládání zvukových dat. Jedna z nejpopulárnějších technologií digitálního zvuku (popularizovaná pomocí CD) je známá jako modulace pulzního kódu (nebo PCM). Zvuk je vybrán v nastavených intervalech a amplituda diskrétní vlny v tomto bodě je uložena jako digitální hodnota zpomocí bitové hloubky vzorku. Lineární PCM (což naznačuje, že amplitudová odezva je lineárně jednotná v odběru vzorků) je standard používaný na CD a v kódování LINEAR16 API řeči. Obě kódování vytvářejí nekomprimovaný byte odpovídající přímo audio datům a obě standardy obsahují 16 bitů hloubky. Lineární PCM používá na discích CD bitovou rychlost 44100 Hz, která je vhodná pro přesun hudby. Avšak vzorkovací frekvence 16000 Hz je vhodnější pro rekompilaci řeči. Lineární PCM (LINEAR16) je příklad nekomprimovaného zvuku, protože digitální data jsou uložena podobným způsobem. Při čtení jednokanálového bajtového proudu zakódovaného pomocí Linear PCM můžete každých 16 bitů (2 bajty) počítat, abyste získali další hodnotu amplitudy signálu. Téměř všechna zařízení mohou manipulovat s těmito digitálními daty nejprve - můžete trimovat zvukové soubory Linear PCM pomocí textového editoru, ale nekomprimovaný zvuk není nejúčinnější způsob přenosu nebo ukládání digitálního zvuku. Z tohoto důvodu většina audia používá metody digitální komprese.
Krátký zvuk
Zvuková data, stejně jako všechna data, jsou často komprimována pro usnadnění skladování a přepravy. Komprese v kódování zvuku může nastat bez ztráty nebo ztráty. Bezplatná komprese může být vybalena k obnovení digitálních dat do původní podoby. Komprese nutně vymaže některé informace během dekompresní procedury a je parametrizována tak, aby indikovala stupeň tolerance k této technicekomprese pro vymazání dat.
Lossless
Lossless komprimovaných digitálních nahrávek s využitím sofistikovaných permutace uložených dat, která nevede ke zhoršení kvality původního digitálního modelu. Bezeztrátové komprese vybalení výstup dat digitalizované informace nebudou ztraceny. Takže, proč metody ztrátové komprese někdy mají optimalizační možnosti? Tato nastavení často zpracovávají velikost souboru pro dekompresní čas. Například, FLAC Použijte úroveň komprese z 0 (nejrychlejší) až 8 (nejmenší velikost souboru). Komprese FLAC vyšší úroveň neztratí žádné informace ve srovnání s kompresním nižší úrovni. Místo toho je kompresní algoritmus stačí strávit více výpočetního výkonu při stavbě nebo dekonstruyrovanyy původního digitálního zvuku. Speech API podporuje dvě bezztrátové kódování: FLAC a LINEAR16. Technicky LINEAR16 není "bezztrátová komprese", protože komprese není primárně zapojena. Je-li pro vás důležitá velikost souboru nebo přenos dat, vyberte možnost FLAC jako možnost kódování zvuku.
Ztráta stlačení
Komprese audio eliminuje nebo redukuje některé druhy informací v konstrukci komprimovaných dat. Speech API podporuje více formátů s ztrát, i když je třeba se vyhnout, protože ztráta dat může mít vliv na přesnost rozpoznávání.
Populární MP3 kodek je příklad ztrátového kódování. Všechny metody komprese ve formátu MP3 odstraňují zvuk z vnější části normálního lidského zvukového pásma a regulují úroveň komprese regulováním účinnýchMP3 datový kodek nebo bitové číslo za sekundu pro uložení data zvuku. Například stereo CD s lineárním PCM s 16 bity má efektivní bitovou rychlost. hloubka Vzorec kódování zvuku: 441,000 * 2 kanály * 16 bitů = 1,411,200 bitů za sekundu (bit /s) = 1411 kbit /s, například, komprimovat MP3 odstraňuje tyto údaje pomocí rychlosti přenosu dat, jako je 320 kb /s, 128 kbit /s nebo 96 kbit /s, což má za následek špatnou kvalitu zvuku. MP3 také podporuje proměnné bitové rychlosti, které mohou dále komprimovat zvuk. Obě metody ztrácejí informace a mohou ovlivnit kvalitu. Je jisté, že většina lidí může určit rozdíl mezi 96kbps nebo 128kbps kódované hudby ve formátu MP3.
Jiné formy komprese
MULAW - 8-bitové kódování PCM, kde amplituda modulovaná vzorek logaritmické spíše než lineárně. V důsledku toho uLaw snižuje efektivní dynamický rozsah komprimovaného zvuku. Ačkoli ulaw byla zavedena speciálně pro optimalizaci kódování řeči, na rozdíl od jiných typů audio, 16-bit LINEAR16 (nekomprimovaný PCM), je stále mnohem lepší než 8-bitového stlačeného zvuku ulaw. AMR kódované a modulované AMR_WB audyokass zavedením variabilní bitové rychlosti výstupního audio vzorku.
Ačkoliv Speech API podporuje více formátů, se ztrátami, měli byste se jim vyhnout, pokud máte kontrolu nad zdroji zvuku. Přestože odstranění těchto dat pomocí ztrátové komprese nemusí poskytovat znatelný vliv na zvuk slyšel lidským uchem, ztráta dat pro mechanismus rozpoznávání řečimůže výrazně zhoršit přesnost.