Výběr konkrétního počtu záznamů z velké sady je dobrý nápad, ale když je soubor skutečně velký, je účinek ponižování nápadu. Výběr více záznamů z určité pozice vytváří skutečný pokles výkonu: před dosažením cíle se MySQL podívá na další položky a tráví čas.
Formát může limit MySQL fungovat od začátku tabulky nebo od jejího konce. Odběr vzorků může určit konkrétní počet vstupů začínajících z dané pozice. Může se stát, že nastane vždy nejhorší situace. Celkový tok zákazníků obvykle určuje obecný statistický režim provozu, je však nutné předpovědět různé situace, je to vážné rozhodnutí ve prospěch stránky.
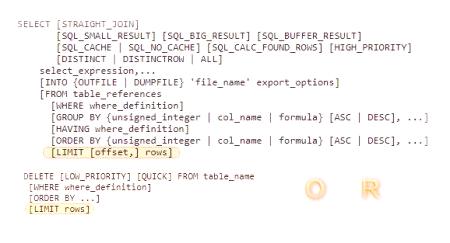
Strukturální syntaxe LIMIT
V oficiálních zdrojích je kontextová syntaxe MySQL označena jako zobrazená na obrázku níže v kontextu dotazů pro výběr a odstranění.
Žádost o výběr vzorku (výběr) zahrnuje dvě čísla: offset "O" a "R", požadavek na smazání je napsán jedním číslem - počet položek "R" je smazán.
Velké hodnoty limitu "O, R"
MySQL limit: syntaxe umožňuje výběr hodnot v libovolném schématu. Základní podmínky: "O" je offset prvního vybraného záznamu, "R" je počet vybraných záznamů. Problém je v tom, že pokud je "O" = 9000, pak předtím, než MySQL vybere záznam 9001, projde první 9000. Pokud je R = 1000, pak celkový vzorek "bude mít" 10 000 záznamů. Limit výběru služby MySQL může fungovat od začátku tabulky nebo od jejího konce v závislosti na směru třídění záznamů asc /desc. Možnost práce od konceTabulky nejsou slibným řešením, i když v některých situacích je obtížné bez nich.
Design, kde velký "R" by měl malý zájem pro vývojáře a uživatele: MySQL delete limit. A to je daleko od všech případů. V tomto návrhu je hlavní zátěž odpovědnosti spjata se stavem vzorku (kde) vymazaných záznamů. Pro bezpečnost a kontrolu procesu vymazávání záznamů je obvykle vývojář zájem o použití mechanismu AJAX a odstranění záznamů v malých částech. Při takovém mechanismu návštěvník stránek nezaznamenává zpoždění při návrhu odstranění.
Vzorek podle jednoho jedinečného záznamu
Správný stav kde a dotaz "limit 1" MySQL bude okamžitě spuštěn. Smazání nebo výběr jedné položky však není vždy dobrým rozhodnutím. Typicky se přírůstkové vzorkování pro všechny položky tabulky používá pro uspořádání dat stránek (například komentáře, články, recenze produktů). Rozhodnutí o vytvoření obsahu webové stránky by mělo být provedeno okamžitě, ale s klasickým použitím limitu MySQL O, R bude rychle vybráno pouze první deset z prvních 100 záznamů a pak začne zpoždění. Zatím ne všechny jsou tak obtížné, můžete si rychle vybrat nahrávku, ale vyhrajete kvůli návrhu a logice výstupu záznamu do prohlížeče prohlížeče.
Nic mu neznemožňuje dělat to velkolepé a skrývat fatální zpoždění v dialogu o tvorbě obsahu.
Relační vztah v MySQL
MySQL je skvělý nástroj pro prezentaci a zpracování informací. Vývojář má dobrý nářek jazykaSQL a vhodný mechanismus pro vytváření dotazů. Chyby a nepředvídané situace jsou zaznamenávány, přístup k datům je spravován až na úroveň základních operací. Všechny nevýhody se týkají samotného konceptu relačních vztahů. Co dělat, tento koncept funguje tak zásadně a spolehlivě, není nic co dělat, jak vzít v úvahu jeho zvláštnosti a vzít je v úvahu. Současná úroveň vývoje hardwaru, vysoce kvalitní implementace funkčnosti všech MySQL nástrojů (limit není výjimkou) zajišťují dostupnost velkých objemů dat při vysokých rychlostech a hlavně vzorkování.
Velké objemy a standardní vyrovnávací paměť
Ukládání dat do paměti před nahráváním a po odběru vzorků - myšlenka je nádherná, pochází ze vzdálenějších 80. let. Ukládání do mezipaměti se stalo módou na všech úrovních zpracování dat z procesoru, sítě, samozřejmě úrovně http serveru a vlastně databází. Vývojář se může obrátit na správce serveru nebo nakonfigurovat v mezipaměti na úrovni Apache a MySQL nebo jinou kombinaci softwaru používaného k poskytování provozu webového zdroje a serveru MySQL.
Toto je normální standardní řešení. Ve většině případů je to obvyklé. V programování je dlouho hledaná myšlenka rozdělení práce. Vývojář dělá stránky, správce spravuje práci všeho, co poskytuje optimalizaci využití webu. V kritických situacích, kdy jsou databázové tabulky velké, se musí vzdát od přijatých kánonů. Potřebujete něco změnit v datové organizaci.
Tablichnapaging organizace
Vývojáři jsou zvyklí: relační databáze - kolekce tabulek, které jsou vzájemně na klávesách. Taková jednoduchá myšlenka, stůl představoval množství podobných stránek se stejným názvem, ale různých indexů, které překračují obvyklý prezentaci.
Ale co je tu vtipné? Tabulka je sada záznamů obsahujících různá data, která odpovídají typům polí (sloupce, hlavičky tabulek). Dotaz dotazu MySQL limit odkazuje na tabulku "big_info" a vybere c 100000 řádkové položky 24 zobrazení v prohlížeči. V tomto rozhodnutí se na vzorku podílí 100024 řádků - je to dlouhá doba. Ale pokud změnit situaci a celý stůl „big_info“ malovat několik set tabulky „big_info [0999]“ 1000 záznamů, problém nastává pouze tehdy, když budete vyzváni MySQL „objednávku * mezní O, R“, protože třídění bude mimořádně obtížné. Nicméně, a to nejen třídit, ale jakékoliv jiné transakční záznamy o všech dostupných prostředků nemožné databázovou tabulku výše, který je reprezentován několika tabulek. V tomto kontextu neexistuje žádný index v MySQL. Relační vztahy poskytují přehlednost: existuje databáze, má tabulky, tabulky - sloupce a záznamy. Existují "lotion": uložené procedury, spouštěče, podmínky a další podrobnosti.
Vlastní paměť a prostředky k
dobrý nápad, „Yandex“ - „tepelné“: teplotní mapa na web. Tento nástroj ukazuje v rozhodnutí o spektrálním zbarvení rozdělení významu návštěvníků na "území" stránky. Zřejmě se objeví nový školní předmět - geografie webové stránky: kde a co umístit. Dobrý doplněk generálaTato myšlenka geografie, území perelozhennaya skvělé záznamy databázové tabulky nám umožňuje formulovat objektivní argument, nikoliv celé území záznamů v poptávce a ne vždy.
Čím větší je proud návštěvníků, tím více zákony na potřeby vzorku. MySQL Limit vždy provedena přesně a vždy s konkrétní důvod. Shromažďovat konkrétní důvody nebude nikdy fungovat. Uchopení za každou konkrétní příčinu MySQL mezní výsledky v každém případě - triviální úkol. Výsledkem není organizace stránkovací tabulky v podobě stovek podobných stránek, a informace poptávka kužel. Pouze v fatálních případů nebo v informační stránky akce u jít na rozsáhlém vzorku velkého množství dat. V normálním režimu - vybrané drobky. Vlastní rychlost vyrovnávací paměti jednoduše vyřešit problém, vzorek je na klíč „zvláštního důvodu“ s malým stolkem výsledků operací posledního vzorku jednoho velkého stolu.
třídění a další velkoobchodní operace
Problém velkého množství dat spočívá na výkon hardware a software. Dnes udělal ohromný výkon, ale objemy dat také prudce vzrostl. Při zvýšení rychlosti a kvality silnic, adekvátní rostoucí potřeba jednat rychle a okamžitě řešit problémy. Jednoduchá obsluha třídění, přidávání záznamů a dat načítání ovlivňuje přímo nebo nepřímo všechny záznamy velkého stolu - potenciální brzda zaručena ztrátu produktivity.
Relačnívztah byl příliš dlouhý na dlaň šampionátu, ale nechat cestu k tomuto dni nemají žádný úmysl: jen nikomu. Jiné varianty organizace dat, které poskytují okamžitou navigaci na velkém objemu informací, dokonce ani nepřišli s super-vůdcem průmyslu "Great Information" - Oracle. Oracle však poskytuje dobré zkušenosti a vynikající znalosti v implementaci jazyka SQL a jeho dialektů. Na funkci MySQL má určitý dotisk kvality. Vývojář může bezpečně používat návrh limitu MySQL na jedné datové tabulce a má volný přístup k velkoobchodním operacím nad tímto velkým stolem.
Přirozené vnímání informací
Člověk vnímá a zpracovává z velké části nevědomky obrovské množství informací, které nejsou k dispozici nejpokročilejším nástrojům společnosti Oracle. Ale na to nemůže být hrdý. Oracle může přenést takové objemy dat a provádět takové třídění, které vyžaduje, aby bylo provedeno více než sto případů lidského života.
Každý musí dělat svou práci a dělat to co nejúčinněji. Vztažné postoje nebudou nikdy vymazány - jsou pro tyto údaje charakteristické, je jejich nedílnou součástí. Implementace databází v relačních vztazích postrádá sémantiku. Klíčová organizace, indexy přístupu k záznamům, není obsah, který poskytuje rychlý přístup k informacím. Konzistentní uspořádání paměti počítače a emulace asociativního přístupu k informacím - skutečný důvod ztráty času při přístupu k velkému stolu k odběru vzorků informací při jejich dodržováníintegrita pro skupinové operace.
Informační objekty a přirozené sdružení
Vyvarujte se sekvence při provádění operací, které vývojář dosud nemůže. Tak uspořádaný počítačový svět. Počítač má jeden procesor a vícejádrové a multiprocesorové varianty - stále to není neurální organizace paralelního zpracování informací, která používá lidské myšlení. Vývoj algoritmu vždy apeluje na jeden proces, i když je rozdělen do mnoha proudů. Programování, dokud je na stejné úrovni, a to i když je kód vytvořen ve formě systému interagujících objektů, kopie, která působí na jejich vlastní. Otázkou je, ne tolik jako na strukturu informačních systémů jako samostatné objekty, ale v prostředí, které zajistí jejich fungování. Středa je konzistentní, ne paralelní. Zvýšení počtu jader a počet procesorů v počítači, tabletu nebo jiného zařízení, neznamená, že je asociativní výpočetní zařízení.
Ale výstup je stále tam: každá konkrétní aplikace je problém, na který potřebujete najít rychlou odpověď. Je třeba provést rychlou volbu (MySQL limitní) navzdory skutečnosti, že další funkce (MySQL objednávku, skupinu, Připojit & amp; kde) nebude ovlivněna, tabulka bude rozdělena do mnoha stejných dílů a mezipaměti postup bude dostávat aktualizace hned po aktualizaci , a ne když obdrží další "konkrétní důvod". Jazyk SQL je dobrý jazyk, ale pokud přidáte přidružení, bude to ještě lepší.