technologie OCR (optické rozpoznávání znaků) může být použita k převedení tištěného dokumentu na elektronickou verzi. Například pokud je skenována vícestranová instance do souboru TIFF, je načten do programu OCR, který rozpozná text a poté jej převede do upravitelného souboru. Některé programy umožňují skenovat stránky a převést obsah do dokumentu v jednom kroku. I když byla technologie původně vyvinutá pro optické rozpoznávání znaků, může být použita i pro ručně psané znaky. Například poštovní služby, jako je USPS, používají OCR software k automatickému zpracování dopisů a balíčků čtením adresy.
Oblast použití OCR
OCR je dekódováno jako optické rozpoznávání znaků. Jedná se o rozšířenou technologii pro rozpoznávání textu uvnitř obrázků jako naskenovaných dokumentů a fotografií. Technologie se používá ke konverzi prakticky jakéhokoli typu obrázku, který obsahuje písemný, ručně nebo tištěný text do strojově čitelných textových dat.
OCR se stala populární na počátku 90. let, kdy se snažila digitalizovat historický materiál. Od té doby metoda podstoupila významná zlepšení a v současné době poskytuje téměř dokonalou přesnost pro optické rozpoznávání znaků. Pokročilé techniky, jako Zonal OCR, se používají k automatizaci složitých pracovních postupů založených nakonverze zadaných textů na digitální dokumenty. Po dokončení zpracování naskenovaného materiálu lze text upravovat pomocí programů, jako jsou aplikace Microsoft Word nebo Dokumenty Google, které jsou textovými editory. Než se tato technologie objevila, jediný způsob, jak digitalizovat tištěné dokumenty, bylo ručně napsat text. Nejen to trvalo hodně času, ale také vedlo k nepřesnostem a chybám při kopírování kopie. OCR je často používán jako „skrytý“ technologie v mnoha známých systémů a služeb, včetně automatizovaného zadávání dat a indexování pro vyhledávače, automatické optické rozpoznávání znaků státních poznávacích značek, stejně jako pomoc nevidomým a zrakově postiženým lidem.
Proces určení přesnosti textu
Každý krok procesu OCR je důležitý pro určení přesnosti konečného textu. Začíná převáděním tištěného dokumentu. Pokud tam jsou stopy, skvrny a špatný kontrast, při detekci software bude dělat chyby, a výsledek bude nesprávná. Chcete-li se vyhnout těmto potížím, můžete vytvořit vylepšenou kopii fotokopie. První etapou práce je skenování tištěného textu. Software OCR pracuje s obrazovými soubory. Skener nebo dobrý digitální fotoaparát vytváří jasné fotokopie dokumentů. Je lepší převést naskenované soubory do černobílé. Proces je binární. Při černé barvě v obraze je rozpoznáno rozpoznávání textu OCR a bílá, naopak, působí jako pozadí. Druhá fáze jedefinice znaků Rychlost tohoto procesu závisí na programu OCR, který používáte. Většina z nich analyzuje každý prvek jeden po druhém. Účelem programu je identifikovat znaky, ale dobré programy rozpoznávají nejen text, ale i tabulky a další prvky rozvržení. Tento proces není dokonalý, protože existuje mnoho faktorů, které ovlivňují přesnost. Jaké programy jsou určeny pro optické rozpoznávání znaků, uvedeme níže. A uživatel si může vybrat, co je nejlepší. OCR mají vestavěné funkce kontroly pravopisu a upozorňují na zavádějící slova. Některé z nich jsou tak složité, že označují nesoulad slov a gramatických chyb, uživatel potřebuje provést potřebnou úpravu. Posledním krokem je uložení dokončeného dokumentu ve správném formátu. Pokud to aplikace nevyžaduje, můžete využít mnoho bezplatných online konvektorů.
Optická technologie pro Braillovo písmo
Technologie optického rozpoznávání znaků (OCR) umožňuje slepým nebo zrakově postiženým lidem definovat text a vyslovit nahlas. Toto využívá jazykový výstup a zobrazuje informace na braillském řádku. Existují tři hlavní prvky optického rozpoznávání znaků: pořizování snímků, rozpoznávání a čtení textu. Nejprve je tištěný dokument zachycen fotoaparátem, software OCR ho převede na rozpoznatelné znaky a slova a syntetizátor v systému vysílá určitý materiál nahlas nebo se zobrazí na braillském displeji. Informace mohouuložené elektronicky na zařízení se softwarem OCR nebo v samostatné paměti zařízení. Proces bere v úvahu logickou strukturu jazyka. Systém usuzuje, že například "to" na začátku návrhu je chyba a měla by být chápána jako "toto". Používá slovní zásobu a používá ověřovací metody podobné těm, které používají v mnoha textových editorech. Všechny systémy OCR vytvářejí dočasné soubory, které obsahují znaky a rozvržení stránky. Na některých systémech je možné je převést na formáty, které lze nalézt pomocí běžně používaných počítačových aplikací, jako je textový editor, tabulkový procesor a databáze.
Výběr programů pro rozpoznávání textu
Doporučuje se, abyste vědomě přistupovali k výběru softwaru pro rozpoznávání textu. Nejlepší je vyzkoušet sebe nebo vzít v úvahu názor pokročilých uživatelů. Testování se provádí s ohledem na následující faktory:
Přesnost je to, co rozlišuje dobrý OCR od špatného. Je však nereálné očekávat 100% přesnost programu rozpoznávání rukopisu. Faktory, jako je kvalita originálních dokumentů a rozlišení obrazu, významně ovlivňují konečný výsledek. Dobré OCR dosáhnou 98% při použití moderního skeneru a zdrojového kódu v uspokojivém stavu.
Vícejazyčnost - Dnes je tato funkce vlastněna většinou programů. OCR skenuje samostatný znak, který ho identifikuje. Je-li určen k rozpoznání pouze anglických písmen, nebude to možnépřesně interpretovat speciální znaky, například písmena, jako jsou písmena označující "e". Toto představují tyto znaky s nejbližším ekvivalentem v angličtině. Při použití aplikace, která podporuje mnohojazyčnost, je určen jazyk dokumentu, který zajistí přesnost rozpoznávání.
Podpora rukopisu. Text vytvořený pomocí klávesnice je snadno rozpoznán libovolným programem. Ručně psaný je však úplně jiný způsob skenování. Lidé mají velmi odlišný rukopis. Někteří píší úhledně, zatímco většina rukopisu není dostatečně čitelná. Kvalitní OCR mohou rozpoznat rukopis. Proto chcete archivovat ručně psaný materiál, potřebujete programy pro rukopis.
Úroveň automatizace. OCR lze spustit automaticky nebo interaktivně. Pokud potřebujete skenovat více stránek najednou, je nejlepší zvážit automatické programy. Pomocí této funkce můžete skenovat dokumenty s několika kliknutími při provádění dalších úloh a je snadné najít výsledný soubor PDF, txt nebo doc. Většina programů pro rozpoznávání textu má omezenou automatizaci.
Zachování uspořádání. Hlavním účelem těchto programů je přeložit text do elektronické podoby. Některé z nich nezachovávají rozvržení původního dokumentu. Proto je nutné upravit finální verzi po dlouhou dobu. Dobrý program by měl zachránit původní rozložení a v konečné kopii je požadována menší kopie. Takové programy ukládají sloupce tabulky a grafické obrázky, stejně jako v původní verzi.
Populární software pro mobilní zařízení
OCR je ideální pro přenos textu z přírodních zdrojů přímo do digitálního dokumentu. Existují různé typy aplikací a aplikací pro stolní i mobilní zařízení. Jsou různé v ceně a mají své vlastní klíčové vlastnosti.
Nejvíce populární "Android" -skanery:
Office Lens - poskytuje skenování a OCR stránky pro uživatele Android-free. Chcete-li převést, musíte se připojit k Internetu.
Skenery PDF (například ABBYY TextGrabber, CamScanner, MDScan, OCR Okamžitě) - provádět skenování a OCR. Neexistují žádné omezení počtu naskenovaných stránek a žádné vodoznaky.
Online OCR. Může se nalézt na internetu, služba je velmi jednoduchá a snadná. Charakteristickým rysem je, že podporuje 46 jazyků, původní dokument neváží více než 5 MB, je snadné převést Microsoft Word, Excel nebo obyčejný textový formát. Po registraci můžete převést vícestranové PDF, RTF, Excel a soubory až do 100 MB. Pro velké objemy rozpoznávání existuje placená verze.
Dokumenty Google
Pro ty, kteří jsou již s dokumenty Google obeznámeni, můžete použít nástroj OCR zabudovaný do Disku Google. Chcete-li dosáhnout nejlepších výsledků, musí být písmo nastaveno na Arial nebo Times New Roman. Výsledek můžete zlepšit tím, že naskenovaný obraz má dokonce světlý a jasný kontrast. Foto materiály mohou být zpracovány jednotlivě do JPG, PNG, GIF nebo vícestránkových dokumentů ve formátu PDF. Rozšíření podporuje většinu jazyků. Google má mnoho tréninkových programů a schopností zpracování cloud. Mnoho uživatelů se domnívá, že služba nemá pokročilé funkce a možnosti. Pokud však používáte aplikaci Google Drive pro Android, můžete skenovat stránky přímo z aplikace pomocí fotoaparátu na smartphonu. V opačném případě stahujte dokumenty pomocí skeneru připojeného k počítači nebo jakýmkoli jiným způsobem spusťte rozpoznávání zpracování na Disku Google. Pro jednotlivce nabízí Disk Google bezplatnou úroveň ukládání přibližně 19 GB, která má možnost rozšířit až 100 GB prostřednictvím Google One za 199 USD. USA
Optické rozpoznání Abbyy
Abbyy FineReader dlouhodobě pracuje s dokumenty. Je to komplexní řešení jak pro firmy, tak pro běžné uživatele. Umožňuje vám získat všechny potřebné funkce pro extrakci obsahu textů z čtecího zařízení v plném rozsahu, úhledně organizovaných digitalizovaných materiálů. Kromě rozpoznávání textu a konverze do formátu PDF, Microsoft Office nebo jiných formátů může program také porovnávat, přidávat poznámky a komentáře. Abbyy FineReader dokáže převádět materiál v dávkovém režimu a zpracovávat mnoho výstupních formátů v 192 různých jazycích. Jsou k dispozici doprovodné mobilní aplikace, když potřebujete provést rychlou kontrolu z telefonu. Software není aktuální, ale je jednoduchý, funkční a pracuje dobře s jeho prací. Nástroj má dobrou reputaci jako jednu z nejlepších možností v oblasti optického rozpoznávání znaků. Můžete použít bezplatnou zkušební verzi. PRO náklady z19999 dolarů US na standardní jednotnou trvalou licenci. Pokud se někdo zdá být drahou možností, můžete mít dobrou alternativu k ABBYY FineReaderu - online verzi. Je omezeno na skenování pouze 10 stránek měsíčně. Ale přichází se všemi ostatními prémiovými funkcemi. Budete se muset zaregistrovat, abyste získali přístup. Podporuje mnoho formátů vstupních souborů a můžete vybrat výstupní soubory jako PDF, Word, Excel, PowerPoint a e-Pub.
Služba Cloud Acrobat
Aplikace Adobe Acrobat splňuje všechny požadavky a nabízí působivý seznam funkcí a možností, i když cena je trochu strmější než konkurence. Pro všechny funkce rozpoznávání optického textu vyberte verzi Pro v aplikaci Adobe Acrobat. DC znamená "Document Cloud" a integruje zcela zřetelně řešení Adobe cloud, pokud chcete přistupovat k vašim souborům z libovolného počítače. K dispozici je také jednoduchá a bezproblémová integrace se všemi ostatními službami Adobe, jako je Photoshop. Pokud se uživatel rozhodne zaplatit za verzi Adobe Acrobat DC, obdrží všechny nástroje pro rozpoznávání textu, možnost přidávat komentáře a zpětnou vazbu k obsahu, specializovanou službu pro skenování tabulek, možnost rychle porovnat dva dokumenty dohromady. Materiály lze upravovat přímo na obrazovce několik sekund po jejich naskenování. Logo Adobe zaručuje určitou úroveň kvality a uživatelé jsou ohromeni intuicí a schopnostmi aplikace Adobe Acrobat DC. Předplatné služby začíná ve výši 1.299 USD. USA
Nejlepší svobodný software
Volný OCR do aplikace Word je nejlepší freewareSoftware pro optické rozpoznávání znaků pomocí nejnovějších mechanismů. Tesseract je nejsilnějším nástrojem pro tento typ a považuje se za jednu z nejpřesnějších metod. Program podporuje více obrazových formátů a TIFF více stránek. Tato služba může být zcela zdarma použitelná k získání textu z poskytnutého fotografického materiálu. Motor Tesseract byl původně vyvinut společností Hewlett Packard Labs v letech 1985-1994. Ke změnám došlo v roce 1996. V roce 1995 byl zařazen do prvních tří uznaných mechanismů. Pracuje s operačním systémem Windows, Linux a Mac OS X. FreeOCR dokáže pracovat s obrázky, které mají vícejazyčný a vícejazyčný text. Spravuje formáty PDF a podporuje zařízení TWAIN, jako jsou skenery, má rozšířené rozhraní s dvojitým oknem, které je snadno pochopitelné.
Volný OCR do aplikace Word může ušetřit spoustu času, aniž byste museli znovu zadat již napsanou práci. Program odebere dokument, naskenovaný objekt nebo obrázek a převede jej na čitelný, upravitelný a přesný materiál. Můžete si jej zdarma stáhnout v aplikaci Word. OCR Word je optimalizován pro práci se všemi typy skenerů a má rating 98% přesností, moderní rozhraní, které umožňuje snadný přístup ke všem úkolům, funkce se uchylují ke spisu není umístěn správně na obrazovce. FOR extrahuje text z pořízených snímků pomocí smartphonů nebo digitálních fotoaparátů s vysokou přesností a kvalitou.
Rozpoznávání znaků v Linuxu
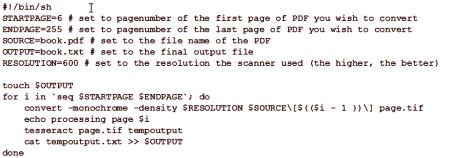
Sada OCRFeeder poskytuje pohodlné grafické uživatelské rozhraní pro Linux.což je v podstatě externí rozhraní pro některé obrázky, OCR a textové nástroje, jako je tisk nebo kontrola pravopisu. Samotné znaky nečte, ale místo toho používá jiné programy OCR prostřednictvím takzvaných nastavení "mechanismů rozpoznávání". Má určité parametry pro Tesseract, CuneiForm, GOCR a Ocrad. Uživatel potřebuje pouze nainstalovat do Ubuntu motory, které si zvolí - jeden nebo více a pak je zjistí v nastavení podavače. Můžete přidat další motory a ručně upravit tato nastavení. V jedné aplikaci může být několik různých motorů. V hlavním okně podavače můžete vybrat, které z nich chcete použít pro konkrétní odvětví, a také je nastaveno, že je vybráno jako výchozí. Chcete-li vybrat jazyk textu čtení, v případě Tesseract a klínového písma, musíte přidat přepínač «-l» s příslušnou jazykovou kódu /skriptu, například, «-l pol» na polském nebo «-l dan-frak» dánských nastavení motoru Technologie optického rozpoznávání tištěných znaků "Tesseract" na začátku rozpoznávala text v angličtině, verze 2.x ji činila vícejazyčnou. V případě potřeby můžete nainstalovat více než jeden slovník. Nové verze digitalizují text podle ISO 963-2. Po úspěšné instalaci použijte příkaz "tesseract & gt; image path & gt; základní název výstupního souboru". Tesseract automaticky přidá zdrojový soubor s příponou .txt, můžete zadat volbu -l a kód jazyka. Pro verze Tesseractu starší než třetí, je velmi důležité, aby byl obrázek ve formátu souboru tagů trochu podobnýrozšíření ".tif", ne ".tiff". Příkazový řádek by měl vypadat takto: "$ tesseract ~ /input.tif output". Kde "input.tif" je transformační dokument umístěný v domovské složce a "výstup" je materiál, který Tesseract vytvoří jako "output.txt". Často naskenované texty jsou uloženy jako rastrový obrázek ve velkém PDF dokumentu. Pomocí aplikace ImageMagick lze jednotlivé stránky vyexportovat jako soubory TIFF pro zpracování z Tesseractu. Následující skript může pomoci tento proces automatizovat.
Program CuneiForm je dalším systémem rozpoznávání textu, který byl původně vyvinut a založen na open source Cognitive Technologies. Verze systému Windows, která má vlastní grafické rozhraní, může být spuštěna s některými výsledky ve Wine. Jeho port Linux je vyvíjen na Launchpadu a přestože v současné době nemá vlastní grafické rozhraní, může být CuneiForm úspěšně spuštěn z grafického rozhraní OCRFeeder. Níže je příklad, jak úspěšně převést některé screenshoty výkresových obrázků .jpeg do užitečných textových souborů online.
Pdfocr je skript, který provádí OCR pro vícestránkové soubory PDF a implementuje jej jako vyhledávatelnou textovou vrstvu. Může používat Tesseract nebo klínový tvar jako mechanismus rozpoznávání. Samotný skript lze získat od společnosti Github nebo PPA. Pro spuštění příkazu napište do terminálu: "pdfocr -i input.pdf -o output.pdf". Technologie OCR nezůstává klidná a dlouhodobě rozpozná intelektuální systém optického rozpoznávání znaků - ICR. Tento standard je pokročilý. Skvěléčást ICR má systém sebevyučení nazývaný neuronová síť, která automaticky aktualizuje databázi nových vzorů rukopisu. Rozšiřuje užitečnost skenovacích zařízení pro účely zpracování dokumentů z rozpoznání tištěného textu (funkce OCR) na ručně psané materiály a při čtení ručně psaného materiálu ve strukturovaných formách může dosáhnout přesnosti přesahující 97%.