Jak se dostat k kurzům v oblasti propagace SEO, nováčci se setkají s velkým počtem srozumitelných a ne velmi včasných. To vše není snadné pochopit, zvláště jestliže zpočátku to bylo špatně vysvětleno nebo ztratilo některé momenty. Zvažte hodnotu v souboru robots.txt Zakázat soubor, který vyžaduje tento dokument, jak jej vytvořit a pracovat s ním.
Jednoduše
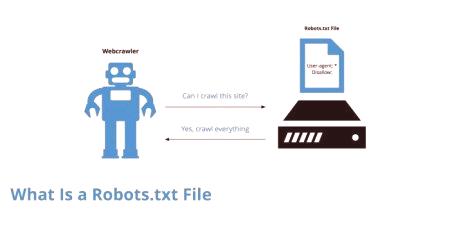
Abychom čtenáři "neposílali" složitými vysvětleními, které se obvykle nacházejí na specializovaných místech, je lepší vysvětlit vše "na prstech". Vyhledávací nástroj přichází na vaše stránky a indexuje stránky. Po zobrazení zpráv, které poukazují na problémy, chyby atd.
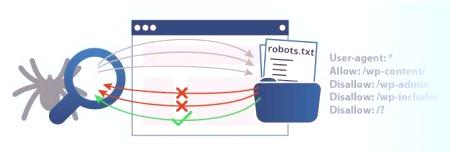
Ale stránky také obsahují takové informace, které se nevyžadují pro statistiky. Například na stránce "Společnost" nebo "Kontakty". To vše je volitelné pro indexování a v některých případech je nežádoucí, protože může statisticky deformovat. Chcete-li tomu zabránit, je nejvýhodnější zavřít tyto stránky od robota. Přesně to vyžaduje příkaz v souboru robots.txt Zakázat.
Standard
Tento dokument je vždy k dispozici na těchto stránkách. Jeho tvorba se zabývá vývojáři a programátory. Někdy to mohou dělat i vlastníci zdroje, zejména pokud jsou malé. V tomto případě práce s ním netrvá dlouho. Robots.txt se nazývá standard vyloučení vyhledávače. Předkládá se dokladem, ve kterém jsou předepsána hlavní omezení. Dokument je umístěn v kořenovém adresáři zdroje. V tomto případě je možné jej nalézt podél cesty "/robots.txt". Pokudzdroj má několik subdomén, pak je tento soubor umístěn do kořene každého z nich. Standard je průběžně spojen s jiným - soubory Sitemap.
Mapa stránek
Chcete-li porozumět úplnému obrazu toho, o čem se diskutuje, pár slov o souborech Sitemap. Toto je soubor napsaný ve formátu XML. Uloží všechna data o zdroji pro PS. Dokumenty se dozvíte o webových stránkách indexovaných dílem.
Soubor poskytuje rychlý přístup k PS na libovolnou stránku, zobrazuje nejnovější změny, frekvenci a důležitost PS. Podle těchto kritérií robot nejsprávněji skenuje místo. Je však důležité pochopit, že přítomnost takového souboru nezajistí, že jsou všechny stránky indexovány. Jedná se spíše o náznak cesty na tento proces.
Použití
Správný soubor robots.txt se používá dobrovolně. Samotný standard se objevil v roce 1994. Byl přijat konsorciem W3C. Od tohoto okamžiku se začalo používat téměř na všech vyhledávačích. Je vyžadována pro "dávkovanou" úpravu skenování zdrojů pomocí vyhledávacího robotu. Soubor obsahuje soubor pokynů, které používají FP. Díky sadě nástrojů je snadné instalovat soubory, stránky a adresáře, které nelze indexovat. Robots.txt také odkazuje na soubory, které je třeba okamžitě zkontrolovat.
Proč?
Navzdory skutečnosti, že soubor lze skutečně použít dobrovolně, je vytvořen prakticky všemi stránkami. To je zapotřebí pro zjednodušení práce robota. V opačném případě bude kontrolovat všechny stránky v náhodném pořadí a kromě toho, že bude moci přeskočit některé stránky, vytvoří velké zatíženízdroje Soubor se také skrývá z očí vyhledávače:
Stránky s osobními údaji návštěvníků.
Stránky obsahující formuláře pro odesílání dat atd.
Zrcadlové stránky.
Stránky s výsledky vyhledávání.
Pokud zadáte soubor robots.txt Disable pro určitou stránku, existuje šance, že se bude stále objevovat ve vyhledávači. Tato možnost může nastat, pokud je odkaz na stránku umístěn na některém z externích zdrojů nebo uvnitř vašeho webu.
Směrnice
Když hovoříme o zákazu vyhledávače, často se používá termín "směrnice". Tento termín je znám všem programátorům. Často se nahrazuje synonymem "instrukce" a používá se ve spojení s "příkazy". Někdy to může být reprezentováno sadou konstrukcí programovacích jazyků. Direktiva Disallow v souboru robots.txt je jedním z nejčastějších, ale nikoliv jediných. Kromě toho existuje několik dalších, kteří jsou zodpovědní za určité pokyny. Existuje například uživatelský agent, který zobrazuje vyhledávací roboty. Povolit je opak příkazu zakázat. Označuje povolení procházení některých stránek. Dále se podívejme na základní příkazy.
Vizitka
Samozřejmě, v souboru robots.txt není uživatelský agent Disallow jedinými směrnicemi, ale jedním z nejběžnějších. Skládá se z většiny souborů pro malé zdroje. Vizitka pro libovolný systém je stále příkazem User Agent. Toto pravidlo je navrženo tak, aby odkazovalo na roboty, které se dívají na instrukce, které budou zapsány v dokumentu. V současné době existuje 300 vyhledávačů. Pokud chcete, aby každý z nich následovalNěkteré indikace by člověk neměl vše přepracovat sotva. Bude stačit specifikovat "User-agent: *". "Asterisk" v tomto případě zobrazí systémy, které jsou určena pro všechny vyhledávače. Pokud vytváříte pokyny pro Google, musíte zadat jméno robota. V takovém případě použijte Googlebot. Je-li dokument uveden pouze název, zatímco ostatní vyhledávače nebude akceptovat příkaz souboru robots.txt:. Zakázat, Povolit, a tak dále D. Budou předpokládat, že dokument je prázdný, a nemají žádné pokyny.
Úplný seznam botnových jmen naleznete na internetu. Je to velmi dlouhá, takže pokud budete potřebovat návod pro konkrétní služby Google nebo Yandex, budou muset být konkrétní názvy.
Zákaz
Už několikrát jsme mluvili o dalším týmu. Zakázat specifikuje, které informace by robot neměl číst. Pokud chcete, vyhledávače ukázat všechny jejich obsah spíše než psát «Disallow:». Práce tedy prohledá všechny stránky vašeho zdroje. Úplný zákaz indexování souboru robots.txt "Disallow: /". Pokud píšete tímto způsobem, nebude práce vůbec skenovat zdroj. To se obvykle provádí v časných stádiích, v rámci přípravy na zahájení projektu, experimenty a tak dále. D. V případě, že web je připraven ukázat sebe, pak ji změnit, takže uživatelé mohou poznat ho. Obecně je tým univerzální. Může blokovat určité položky. Například složka příkaz «Disallow: /Papka /», může zabránit skenování odkaz na soubor určitých dokumentů nebo povolení.
Povolení
Povolení prácezobrazovat určité stránky, soubory nebo adresáře pomocí směrnice Povolit. Někdy je třeba, aby robot navštívil soubory z konkrétní části. Pokud je například online obchod, můžete zadat adresář. Další stránky budou skenovány. Nezapomeňte však, že musíte nejprve zastavit zobrazení webu z celého obsahu a zadat příkaz Příjem s otevřenými stránkami.
Zrcadla
Další hostitelská směrnice. Nejsou používány všemi webmastery. Je potřeba, pokud váš zdroj zrcadlí. Toto pravidlo je nutné, protože označuje práci "Yandex", na které z zrcadel je hlavní a která musí být skenována. Systém se nestará a snadno zjistí potřebný zdroj podle pokynů popsaných v souboru robots.txt. V samotném souboru je místo napsáno bez indikace "http: //", ale pouze pokud pracuje na protokolu HTTP. Pokud používá protokol HTTPS, pak tuto předponu označuje. Například "Host: site.com" v případě HTTP nebo "Host: https://site.com" v případě HTTPS.
Navigátor
Již jsme hovořili o souborech Sitemap, ale o samostatném souboru. Když se podíváme na pravidla pro psaní souboru robots.txt s příklady, vidíme použití podobného příkazu. Soubor odkazuje na soubor Sitemap: http://site.com/sitemap.xml. To je provedeno tak, aby robot zkontroloval všechny stránky, které jsou uvedeny na mapě webu na adrese. Při každém návratu se robot zobrazí nové aktualizace, provedené změny a rychlejší odesílání dat do vyhledávače.
Další příkazy
Toto byly základní pokyny, které ukazují na důležité a nezbytné příkazy. Existují méně užitečné apokyny nejsou vždy používány. Například Zpoždění prolézání určuje dobu, která se má použít mezi načtením stránky. To je vyžadováno pro slabé servery, aby nebyly "vloženy" do robotů robotů. Pro určení parametru se používají sekundy. Parametr Clean-param pomáhá vyhnout se duplicitnímu obsahu, který se nachází na různých dynamických adresách. Vznikají, pokud existuje třídící funkce. Bude to vypadat takto: "Clean-param: ref /catalog /get_product.com".
Univerzální
Pokud nevíte, jak vytvořit správný soubor robots.txt - ne strašidelný. Kromě pokynů existují univerzální verze tohoto souboru. Mohou být umístěny na prakticky libovolné webové stránce. Výjimka může být jen skvělý zdroj. V tomto případě by však měly být soubory odborníkům známy a zapojeny do zvláštních osob.
Univerzální soubor směrnic umožňuje otevřít obsah webu pro indexování. Zde je název hostitele a je zobrazena mapa webu. Umožňuje robotům vždy přístup ke stránkám, které je třeba skenovat. Předpokládá se, že data se mohou lišit v závislosti na systému, který má váš zdroj. Proto je třeba zvolit pravidla při pohledu na typ webu a CMS. Pokud si nejste jisti, že soubor, který jste vytvořili, je správný, můžete jej zkontrolovat v Nástrojích pro webmastery Google a Yandex.
Chyby
Pokud pochopíte, co znamená Disallow v souboru robots.txt, to nezaručuje, že při vytváření dokumentu nebudete dělat chyby. Existuje řada typických problémů, s nimiž se setkávají nezkušení uživatelé. Často zaměňujte hodnotu směrnice. Může to býtje spojena s nedorozuměním a nevědomostí o pokynech. Možná jste to ignorovali a přerušili nedbalost. Například mohou používat "/" pro User-Agent a pro Disallow jméno je robot. Převod je další častou chybou. Někteří uživatelé se domnívají, že seznam zakázaných stránek, souborů nebo složek by měl být uveden jeden po druhém za sebou. Ve skutečnosti musíte pro každý zakázaný nebo přípustný odkaz, soubor a složku napsat příkaz znovu a z nového řádku. Chyby mohou být způsobeny nesprávným názvem samotného souboru. Pamatujte, že se nazývá "robots.txt". Použijte malá písmena pro název bez variací jako "Robots.txt" nebo "ROBOTS.txt".
Pole User-agent by mělo být vždy vyplněno. Nenechávejte tuto směrnici bez příkazu. Při opětovném návratu k hostiteli nezapomeňte, že pokud web používá protokol HTTP, nemusíte jej zadávat v příkazu. Pouze pokud je to pokročilá verze protokolu HTTPS. Nemůžete ponechat směrnici Disallow bezvýznamnou. Pokud to nepotřebujete, jednoduše to neříkejte.
Závěry
Shrnutí, stojí za to říct, že robots.txt je standard, který vyžaduje přesnost. Pokud jste se s ním nikdy nesetkali, pak v raných fázích stvoření budete mít mnoho otázek. Nejlepší je dát tuto práci webmasterům, protože pracují s dokumentem po celou dobu. Navíc může dojít k určitým změnám ve vnímání směrnic vyhledávači. Pokud máte malý web - malý internetový obchod nebo blog - pak stačí studovat tuto otázku a vzít jeden z univerzálních příkladů.