Formální návrhový soubor získává obsah PHP je podobný souboru, ale čte obsah do řetězce spíše než pole řádků a umožňuje zadat posun v souboru, z něhož má začít číst.
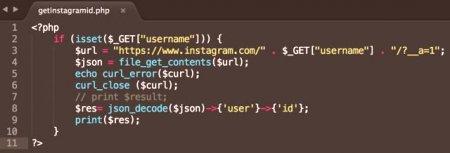
Syntaxe a příklad použití

Obvykle je jednodušší verze souboru získává obsah PHP:

. Zadána specifikovaná adresa URL. Ve skutečnosti je stránka
reprezentována konstrukcí PHP phpinfo (), tj. Text ze tří řádků není čten a výsledek této funkce.
 Jak je možné vidět, výsledkem je celé stránky, zatímco design PHP dostat obsah souboru na (http) číst a zaznamenal domácí obsah této stránky v proměnné $ Cline.
Je třeba připomenout, že použití parametru $ kontextu otevírá velké možnosti.
Jak je možné vidět, výsledkem je celé stránky, zatímco design PHP dostat obsah souboru na (http) číst a zaznamenal domácí obsah této stránky v proměnné $ Cline.
Je třeba připomenout, že použití parametru $ kontextu otevírá velké možnosti.
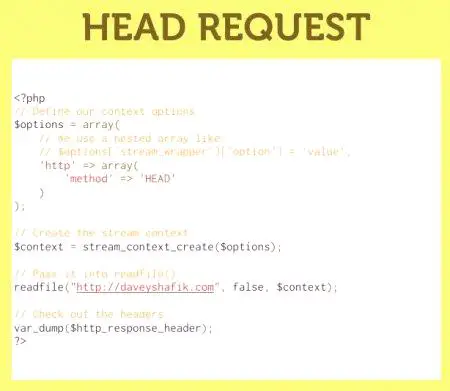 V běžné praxi používat všechny parametry s výjimkou $ jméno souboru, ne populární pravidlo. Hodnota je však vytvořenaStruktura stream_context_create () a použitá jako kontext parametru $, umožňuje psát spíše složité algoritmy pro získání požadovaných informací. Různé souborové systémy, obaly vyžadují různá nastavení a možnosti pro popis kontextu. Může být vytvořen pomocí konstrukcí stream_context_create (stream_context_set_option, stream_context_set_params).
Namísto specifické adresy URL může být parametr $ filename reprezentován názvem proměnné. To vám umožní analyzovat obsah stránek v automatickém programovatelném režimu, zjistit jména stránek, identifikovat odkazy a získat potřebné informace.
V běžné praxi používat všechny parametry s výjimkou $ jméno souboru, ne populární pravidlo. Hodnota je však vytvořenaStruktura stream_context_create () a použitá jako kontext parametru $, umožňuje psát spíše složité algoritmy pro získání požadovaných informací. Různé souborové systémy, obaly vyžadují různá nastavení a možnosti pro popis kontextu. Může být vytvořen pomocí konstrukcí stream_context_create (stream_context_set_option, stream_context_set_params).
Namísto specifické adresy URL může být parametr $ filename reprezentován názvem proměnné. To vám umožní analyzovat obsah stránek v automatickém programovatelném režimu, zjistit jména stránek, identifikovat odkazy a získat potřebné informace.
 Můžete si vytvořit vlastní analyzátor stránek, vyhledávač a naprogramovat distribuované programy pro zpracování informací. Úloha je skutečná, zajímavá a praktická.
Neexistuje žádný problém, co přesně číst soubor. V následujícím, složitý design, get file content php je příkladem toho, že soubor "vordovsky" lze číst bez problémů:
Můžete si vytvořit vlastní analyzátor stránek, vyhledávač a naprogramovat distribuované programy pro zpracování informací. Úloha je skutečná, zajímavá a praktická.
Neexistuje žádný problém, co přesně číst soubor. V následujícím, složitý design, get file content php je příkladem toho, že soubor "vordovsky" lze číst bez problémů:
 Zde je komplexní dokument, který se používá k testování knihovny PHPOffice /PHPWord. Soubor MS Word (* .docx) je známý jako zip archiv, uvnitř kterého jsou informace založeny na standardu Open XML. Obvykle jsou soubory dokumentů dostatečně velké a komplikované, ale soubor získá strukturu obsahu PHP dokáže zpracovat jejich čtení bez obtíží. Specifičnost tohoto příkladu spočívá v tom, že zpracování dokumentů je čistě prostředkem knihovny PHPOffice /PHPWord, která vám neumožňuje získat potřebné schopnosti, a to prostě není možné číst soubor postupně. InTyto dokumenty všechny jeho prvky (slova, odstavce, formule, design, prvky psaní) popisuje řadu značek, některé mohou být reprezentovány posloupnost vnořených objektů.
Zde je komplexní dokument, který se používá k testování knihovny PHPOffice /PHPWord. Soubor MS Word (* .docx) je známý jako zip archiv, uvnitř kterého jsou informace založeny na standardu Open XML. Obvykle jsou soubory dokumentů dostatečně velké a komplikované, ale soubor získá strukturu obsahu PHP dokáže zpracovat jejich čtení bez obtíží. Specifičnost tohoto příkladu spočívá v tom, že zpracování dokumentů je čistě prostředkem knihovny PHPOffice /PHPWord, která vám neumožňuje získat potřebné schopnosti, a to prostě není možné číst soubor postupně. InTyto dokumenty všechny jeho prvky (slova, odstavce, formule, design, prvky psaní) popisuje řadu značek, některé mohou být reprezentovány posloupnost vnořených objektů.
Vezmeme-li jako příklad dokumentu (* .docx) stoly, situace není vyřešen v sekvenčním souboru zpracování. Budete potřebovat alespoň dva průchody skrz tělo dokumentu, ne-li jít zejména například hnízdění tabulky navzájem.
Při čtení složitých souborů žádný problém, problém je jednoduchý pro práci se soubory. Nejprve byste měli mít axiom: struktura souboru získat obsah PHP čte správně. I když nepoužíváte tyto nebo jiné parametry, nejjednodušší verze aplikace bude fungovat vždy, jak to mělo být. Problémy způsobují rohové závorky a kódování souborů. Práce v rámci algoritmu by měly být odlišeny od zobrazení výsledku v okně prohlížeče. Postava příkladem vordivskoho souboru linky
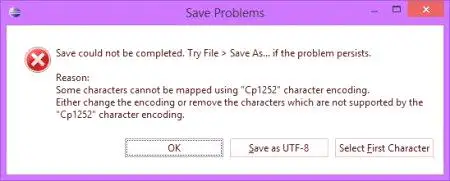 Další okamžik: kódování souborů. Ne vždy jednoduchý textový soubor nevytváří problémy. Při čtení textových informací může přítomnost n dopisů způsobit určité potíže
Další okamžik: kódování souborů. Ne vždy jednoduchý textový soubor nevytváří problémy. Při čtení textových informací může přítomnost n dopisů způsobit určité potíže
Možnosti a kontextové parametry
Hromadné zpracování stránek
Čtení textových souborů
Vezmeme-li jako příklad dokumentu (* .docx) stoly, situace není vyřešen v sekvenčním souboru zpracování. Budete potřebovat alespoň dva průchody skrz tělo dokumentu, ne-li jít zejména například hnízdění tabulky navzájem.
Problémy s kódováním a spetssymvolov
- $ Cline = scChangeLTGT ($ Cline) - volá transformaci dvojice úhelníků speciální znaky „“, nebo jednoduše číst soubor nemůže být vždy zobrazí v okně prohlížeče. Jak psát tuto funkci - nevadí, ale výrazně neměli zapomínat, že číst informace mohou zahrnovat tagy XML a HTML, a to vyžaduje zvláštní pozornost.
. $ cLine = iconv ('UTF-8', 'CP1251',$ cLine). V tomto kontextu je použití funkce iconv () se správným směrem konverze relevantní nejen pro PHP, "pro získání obsahu souboru http: //" pro čtení stránky webu, ale také pro čtení běžného lokálního souboru. Pokud je výsledek čtení "neviditelný", je třeba nejprve zkontrolovat kódování znaků.