Kódováním informací v počítači odkazuje na proces transformace na formu, která umožňuje organizovat pohodlnější přenos, ukládání nebo automatické zpracování těchto dat. Na tento účel se používají různé tabulky. Kódování ASCII je první systém vyvinutý ve Spojených státech pro práci s anglickým textem, který byl následně distribuován po celém světě. Jeho popis, vlastnosti, vlastnosti a další použití jsou věnovány článku níže.
Displej a uchovávat informace v počítači
Symboly na obrazovce počítače nebo konkrétní mobilní digitální gadgets jsou založeny na různých sad vektorových tvarů značení kód, který vám umožní najít mezi nimi i znak, který chcete vložit potřebujeme místo. Je to posloupnost bitů. Každý znak tedy musí odpovídat množině nul a jednotek, které jsou v určitém, jedinečném pořadí.
Jak to všechno začalo
Historicky první počítače byly anglicky mluvící. K kódování informací o znaku v nich stačilo použít pouze 7 bitů paměti, zatímco pro tento účel přiděleno 1 bajt, sestávající z 8 bitů. Počet znaků, které počítač pochopil v tomto případě, byl pouze 128. Tyto znaky sestávaly z anglické abecedy s interpunkčními značkami, čísly a některými speciálními znaky. Sedmibitové kódování v anglickém jazyce s odpovídající tabulkou (kódová stránka), vyvinuté v roce 1963, bylo nazváno americkým standardním kódem pro informaceVýměna Obvykle je používána zkratka "ASCII Encoding", která byla použita k jejímu určení.
Přechod na mnohojazyčnost
Počítače se časem používají v neanglicky mluvících zemích. V souvislosti s tím byla potřeba kódování, které umožňuje používání národních jazyků. Bylo rozhodnuto, že nenasvítíme kolo a že jsme založili ASCII. Kódovací tabulka v novém vydání se výrazně rozšířila. Pomocí 8. bitů můžete přeložit 256 znaků do jazyka počítače.
Popis
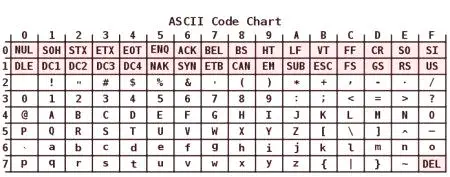
Kódování ASCII má tabulku, která je rozdělena na 2 části. Všeobecně uznávaná mezinárodní norma se považuje za její první polovinu. To zahrnuje:.
znaků se sériovým číslem od 0 do 31 kódovaných sekvencí od 00000000 do 00011111. jsou vyhrazeny pro řídicí znaky, které kontrolují proces odstraňování text na obrazovce nebo porci tiskárny, zvuku a tak dále P. znaků NN v tabulce 32, 127 kódovaných sekvencí z 00100000 až 01111111 se skládá ze standardního stolu. Patří mezi ně prostor (N 32), přičemž písmena abecedy (velká a malá), desetimístné číslo od 0 do 9, interpunkční znaménka, závorky různých tvarů a dalších symbolů., znaky s pořadovými čísly od 128 do 255 kódovaných sekvencí od 10000000 do 11111111. Patřily k nim písmena národních abeced jiných než latina. Tato alternativní část kódovací tabulky ASCII slouží k převodu ruských znaků do počítačové podoby.Některé vlastnosti
Zvláštní funkce zahrnují kódování ASCII na rozdíl od písmena «A» - «Z» dolní a horní registry pouze jeden bit. Tato okolnost značně zjednodušuje transformaci registru a také jeho ověření, že patří k danému rozsahu hodnot. Kromě toho jsou všechny znaky v ASCII kódování systemis představili své vlastní sériová čísla v abecedě, napsal pět čísel ve dvojkové soustavě, na něž se malá písmena v hodnotě 011 2, a horní - 010 2.
Mezi funkce lze přičíst kódování ASCII a prezentace 10 číslic - „0“ - „9“. Ve druhém systému začínají číslem 00112 a končí dvěma čísly. Ano, 0101 2 desyatychnomu ekvivalentní číslo pět jako symbol „5“ je psán jako 001101012. Na základě výše uvedeného, je snadné převést binární desetinná čísla v ASCII kódovaného řetězce přidáním sekvence bitů zleva každé polubaytu 00112.
„Unicode“
Je známo, k zobrazení textu v jazycích, skupiny z jihovýchodní Asie je třeba tisíce znaků. Nejedná se o číslo je popsáno v jeden bajt informací, takže i prodloužená verze ASCII nemohla uspokojit rostoucí potřeby uživatelů z různých zemí.
To znamená, že je třeba vytvořit univerzální kódování, která se vyvíjí ve spolupráci s mnoha světovými vůdci zabývajících se IT průmysl konsorcium Unicode. Jeho specialisté vytvořili systém UTF 32. V něm kódoval 1 znak přidělený 32 bitů, který se skládal ze čtyř bajtů informací. HlavnímNevýhodou bylo prudké zvýšení množství pamětí, které bylo zapotřebí až čtyřikrát, což znamenalo spoustu problémů. Současně platí, že pro většinu zemí s úředními jazyky, které patří do indoevropské skupiny, počet bodů 2 32 je více než přebytek. V důsledku další práce odborníků z konsorcia Unicode se objevilo kódování UTF-16. To se stalo možností konverze symbolických informací, které se skládaly jak o množství požadované paměti, tak o počet zakódovaných znaků. To je důvod, proč byl UTF-16 přijat standardně a v něm pro jeden znak je nutné rezervovat 2 bajty. I tato poměrně pokročilá a úspěšná verze Unicode měla některé nevýhody a po přepnutí z rozšířené verze ASCII na UTF-16 byla váha dokumentu zdvojnásobena. V tomto ohledu bylo rozhodnuto používat kódování s proměnnou délkou UTF-8. V tomto případě je každý symbol zdrojového textu zakódován v sekvenci dlouhé 1 až 6 bajtů.

Odkaz na americký standardní kód pro výměnu informací
Všechny znaky v latinské abecedě v UTF-8 proměnné délky jsou zakódovány v 1 bajtu, stejně jako v kódovacím systému ASCII. Funkce UTF-8 spočívá v tom, že pokud je text v latině bez použití dalších znaků, dokonce i programy, které nerozumí Unicode, budou stále umožňovat čtení. Jinými slovy, základní část textového kódování ASCII jednoduše přejde do nové proměnné délky UTF. Cyrilitické znaky v UTF-8 zaujímají 2 bajty a například gruzínské - 3 bajty. Vytvoření UTF-16 a 8 vyřešilo hlavní problém vytvoření jediného kódového prostoru v fontech. SOd té doby mohou výrobci fontů vyplňovat tabulku pouze s vektorovými formami textových znaků založených na jejich potřebách.
Různé operační systémy dávají přednost různým kódům. Aby bylo možné číst a upravovat texty napsané v jiném kódování, používají se programy pro překódování ruského textu. Některé textové editory obsahují zabudované enkodéry a umožňují vám číst text bez ohledu na kódování.
Nyní víte, kolik znaků v kódování ASCII a jak a proč byl vyvinut. Samozřejmě, že dnes nejrozšířenější na světě obdržel standardní Unicode. Nemělo by však být zapomenuto, že je založeno na ASCII, takže hodnota jejích vývojářů v oblasti IT by měla být správně oceněna.