Unicode je mezinárodní standard pro kódování znaků, který umožňuje zobrazit text na libovolném počítači na světě stejným způsobem bez ohledu na použitý systémový jazyk.
Základy
Chcete-li pochopit, co je požadována tabulka znaků Unicode, nejprve porozumíme mechanismu zobrazení textu na obrazovce monitoru. Počítač, jak víme, zpracovává veškeré informace digitálně, ale aby to dokázal za správné vnímání osoby, musí být v grafice. Takže abychom si mohli přečíst tento text, musíme vyřešit alespoň dvě úlohy:
Kódované tištěné znaky v digitální podobě.
Umožněte operačnímu systému porovnávat digitální formu s vektorovými symboly, jinými slovy najít správná písmena.
První kódování
Za předchůdce všech kódování se považuje americká ASCII. Popisuje anglickou abecedu interpunkčními a arabskými číslicemi. 128 znaků, které se v něm používají, se staly základem dalšího vývoje - používá se i moderní tabulka znaků Unicode. Dopisy latinské abecedy jsou od té doby na prvním místě v jakémkoli kódování.
Všechny znaky ASCII umožnily uložení 256 znaků, ale od prvních 128 latinských, zbylých 128 bylo použito celosvětově k vytvoření národních standardů. Například v Rusku vznikly CP866 a KOI8-R. Tyto varianty byly nazývány rozšířenímiVerze ASCII.
Kódované stránky a Crazzybras
Další vývoj technologií a vznik grafického rozhraní vedly k vytvoření kódu ANSI americkým institutem pro normalizaci. Pro ruské uživatele, zejména se zkušenostmi, je její verze známá jako Windows 1251. Nejprve uvedla koncept "kódové stránky". Bylo to pomocí kódových stránek, které obsahovaly symboly národních písmen, s výjimkou latiny, existovalo "vzájemné porozumění" mezi počítači používanými v různých zemích.
Nicméně přítomnost velkého počtu různých kódování použitých pro stejný jazyk začala způsobovat problémy. Byly tam takzvané karkozybrzy. Vznikly z rozporu mezi stránkou zdrojového kódu, ve které byly vytvořeny některé informace, a kódovou stránkou, která je ve výchozím nastavení použita na počítači koncového uživatele.
Jako příklad lze citovat výše uvedené cyrilské kódování CP866 a KOI8-R. Písmena v nich se lišila v kódových pozicích a zásadách umístění. V prvním byly uspořádány v abecedním pořadí av druhém - libovolným způsobem. Můžete si představit, co se dělo před očima uživatele, který se pokoušel o otevření takového textu, aniž by potřeboval kódovou stránku nebo špatně interpretoval počítač.
Vytváření Unicode
Rozšiřování internetu a souvisejících technologií, jako je e-mail, vedlo k tomu, že textové zprávy nakonec přestaly vyhovovat všem. Přední společnosti v oblastiIT vytvořil Unicode Consortium („Consortium Unicode). Povaha zastoupeny ho v roce 1991, s názvem UTF-32 ponechat více než jednu miliardu jedinečný charakter. To byl důležitý krok na cestě k rozluštění texty .
První univerzální tabulka znakových kódů Unicode UTF-32 však nebyla široce distribuována. Hlavním důvodem byla redundance uložených informací. Rychle bylo odhadnuto, že v případě zemí, které používají latinku, kódovaných pomocí nové univerzální tabulky, text se bude konat čtyřikrát víc, než pomocí tabulek ASCII.
Vývoj Unicode
Následující tabulka znaků UTF-16 Unicode vyřešila tento problém. Kódování se provádí dvakrát méně bitů, ale zároveň se snížil a počet možných kombinací. Namísto miliard postav je možné uložit pouze 65536. Nicméně se ukázalo natolik úspěšný, že tento počet by rozhodnutí konsorcia byla definována jako základní skladovací mezerou standardní Unicode. Přes tento úspěch, UTF-16 nebude vyhovovat všem, protože objem uložených a přenášených informací je stále zavyschuvavsya dvakrát. Univerzálním řešením je znaková tabulka UTF-8 Unicode s proměnnou délkou zápisu. To může být nazýváno průlomem v této oblasti.
Tedy, se zavedením dvou současných norem znak Unicode vyřešen problém jediného místa pro všechny kód použitý v tomto písma.
Unicode pro ruský jazyk
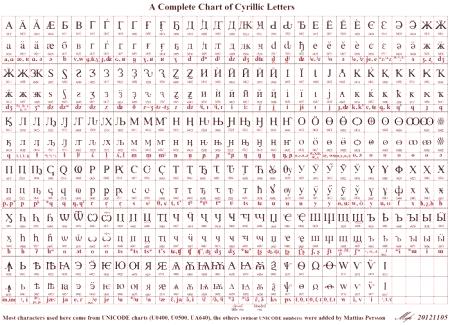
DíkyProměnná délka kódu používaná k zobrazení symbolů, latina je kódována ve formátu Unicode, stejně jako ve vzestupném ASCII, tj. Jeden bit. Pro jiné abecedy může vypadat obrázek jinak. Například znaky gruzínské abecedy se používají k zakódování tří bajtů a znaky azbuky jsou dva. To vše je možné v rámci standardu Unicode UTF-8 (mapa znaků). Ruština nebo cyrilská abeceda zaujímá 448 pozic v obecném kódovém prostoru rozděleném do pěti bloků.
Tyto pět bloků zahrnuje hlavní cyrilské a církevní slovanské abecedy a další písmena jiných jazyků, které používají azbuku. Řada pozic přidělených odrážet staré formy prezentace písmena cyrilice a 22 pozic z celkového jsou stále zdarma.
Aktuální verze Unicode
Rozhodnutí primární úkol, který měl standardizovat písma a vytvořit pro ně jednotnou oblast kódem „konsorcium“ není přestal pracovat. Unicode se neustále vyvíjí a doplňuje. Poslední verze této normy 9.0 byla vydána v roce 2016. Obsahovalo šest dalších abeced a rozšířený seznam standardizovaných emoji. Je třeba poznamenat, že pro zjednodušení výzkumu se do Unicode přidávají i tzv. Mrtvé jazyky. Dostali takový název, protože lidé, pro které byl příbuzný, neexistují. Tato skupina také jazyk, který přežili pouze formou písemných památek. Inprincip, požádat o přidání znaků do nové specifikace Unicode může někdo. Je pravda, že pro to bude muset vyplnit slušné množství zdrojových dokumentů a strávit spoustu času. Životním příkladem může být historie programátora Terence Edena. V roce 2013 požádal o zařazení do specifikace symbolů, které odkazují na tlačítka pro správu napájení počítače. V technické dokumentaci se používají od poloviny 70. let minulého století, ale před specifikací nebyl 9.0 součástí Unicode.
Tabulka znaků
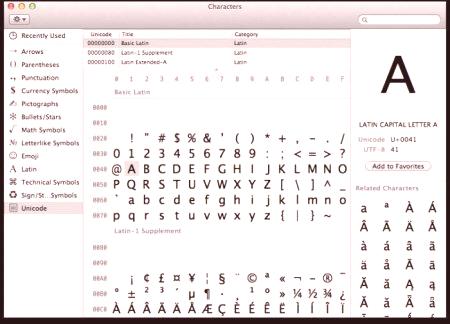
Na každém počítači, bez ohledu na použitý operační systém, tabulka znaků Unicode. Jak používat tyto tabulky, kde je najít a co mohou udělat pro běžného uživatele?
Ve Windows je tabulka symbolů umístěna v sekci menu "Služby". V rodině operačních systémů Linux se obvykle nachází v sekci "Standard" a v MacOS - v nastavení klávesnice. Hlavním účelem této tabulky je zadat znaky do textových dokumentů, které nejsou umístěny na klávesnici. Žádost o tyto tabulky lze nalézt jako široká: od zavedení technických symbolů a ikon národních měnových systémů do psaní příručky o praktické aplikaci karet Tarot.
Na závěr
Unicode se používá všude a vstupuje do našeho života společně s rozvojem internetu a mobilních technologií. Díky svému použití se systém mezinárodních komunikací značně zjednodušil. Můžete to říctzavedení Unicode je orientační, ale zcela neviditelný příklad využití technologie pro společné dobro celého lidstva.