Informace jsou úžasný a mnohostranný výzkumný objekt. Předměty z oblasti pochopení a aplikace fenoménu informací se rychle zvyšují, stejně jako rozsah výzkumu tohoto předmětu, aplikace znalostí v praxi.
V dnešních představách o systémech řízení moci moci je myšlenka relačních vztahů tak velká a neporušená, že všechny ostatní modely prezentace informací jsou stále popsány stejným způsobem.
Statika - základ dynamiky znalostí
Klasifikace podle datového modelu je statická. Pro konstrukci jakéhokoli modelu odborníci shrnou nahromaděný potenciál, kreslí obrazy, vztahy mezi daty a definují (např. Oblast předmětu - zpracování textu):
text je odstavcem nebo mnoha odstavci;
každý odstavec je sestaven z návrhů;
ne každý odstavec má jednu větu;
Každý návrh může obsahovat několik vět nebo slov;
téměř všechny fráze se skládají ze slov;
slova jsou písmena.
Ukazuje se, že struktura databáze a spektra, které byly původně stanoveny, jsou protichůdné. Takový model je formální, závisí na oblasti použití, je vždy předmětem vývoje reprezentací. Ale jakmile malované obrázky a odkazy jsou postaveny, se zdá, že slova mohou obsahovat údaje, aby byl zkratka, název země a slovo, které nevadí, a další bod může obsahovat odkazy na webové zdroje, nebo třemi body. V každém případě to bude mít nový smysl.
Neurčitost významu
Uvádí se: název země. Předpokládaná hodnota je RF =Rusko = Ruská federace. Je to ale také sdružení se SSSR a 15 republikami. Existují další možnosti pro jména různých zemí. Indie = kolonie = vztah s Anglií. America = US = státy = území otevřené Columbusem = území, kde se zástupci jiných zemí shromáždili a vytvořili nový národ, což je z mnoha důvodů kontroverzní.
Slovo, které vůbec nezáleží, může být "adresou" ve specifickém informačním prostoru. Toto je výmluva pro vývoj databázové technologie. Jedna věc je, ale má tolik smyslu, pokud jde o celou technologii, a povinnost přezkoumat klíčové body.
Formát zadaný v datovém modelu formálně nemůže být řetězec znaků, číslo nebo struktura dat. Má-li v něm skutečnou hodnotu, určí obsah a obsah je dynamika spíše než pevný řetězec znaků. Jedná se o faktor nejistoty, který určuje vývoj každého datového modelu.
Koncepce databáze
Význam statického modelu je důležitý. Jedná se o fázi vývoje nápadů, které jsou relevantní v oblasti aplikace a porozumění, které se mohou dále rozvíjet. Na současné úrovni dynamiky znalostních - diskrétní posloupnosti statických modelů - či spíše, série inkarnace nápadů v podobě snadno srozumitelné nejen autora, je ze své mysli, je model v grafiky v komunikacích, popisy softwaru. Podle všeho, „Databáze - informační model ukládání dat organizované skupiny objektů se stejnou sadou vlastností. Informace v databázích jsou uloženy vřádnou formou. "
encyklopedický „poznání“ se obvykle říká: „Databáze je prezentována ve formě objektivního souboru odděleného materiálu (články, výpočty, předpisy, soudní rozhodnutí a podobné materiály), systematizované tak, aby mohly být tyto materiály nalezeny a zpracované pomocí elektronického počítače ". Někteří autoři ve staré (předtím, než počítače staly osobní, přenosné a kapesní) rozlišit konkrétní kohortu, desktop databáze, které obsahují něco méně než terabajt, a nesouvisí s Oracle.
Typy databází
Obecně platí, že definujeme tři směry, typy a významné rozdíly. Je to:
Hierarchická databáze.
Síťová (distribuovaná) databáze.
Relační databáze.
Téměř všichni vědci a odborníci konvergují do jednoho: relační vztahy - základ. Všechny typy databází představují soubor vztahů mezi daty. Dost dlouho na to, aby hierarchickým databázím stromy ve vztahu dynamiky byl viděn: první vrchol byl označen - byl důvod, a druhá větev získal nejvyšší stav.
V praxi databází síťových vedla ke skutečné potřebě nejen k barvě databázi na mnoha serverech, klastrů a lokálních počítačů, ale také provést reverzní projekci: počítače nastavené jiný vzor (model) z jedné databáze na jiný server.
Rozsah také určuje, které typy databází jsou povoleny v informačním prostoruúkol Nepochybně ve většině případů budou existovat jak hierarchické, tak distribuované komponenty. Jak pojmenovat specifické relační vztahy - není podstatné.
Pochopení výhod a nevýhod
Hardwarová součást vstoupila do úrovně jistoty spolehlivosti, rychlosti a účinnosti. Případ malých: součást programu by měla poskytnout svou úroveň kompetence. Někteří autoři odkazují na výhody:
kontrola, redundance, nesoulad dat;
sdílení a zajištění jejich integrity;
bezpečnost, normy, účinnost;
kompromis s protichůdnými požadavky;
dostupnost, produktivita;
snadná údržba, paralelní práce;
Služby zálohování a obnovy.
Ostatní se dívají na výhody odlišně: 39) efektivní využití paměti a vynikající časově náročné ukazatele výkonnosti pro operace;
účinná manipulace s daty;
stejný model lze použít k řešení mnoha problémů;
Jednoduchost simulace a fyzické realizace;
vysoká účinnost zpracování.
Nevýhody jsou obvykle definovány jako:
složitost, velikost, náklady;
náklady na hardware (finance);
náklady na konverzi (výpočetní a dočasné);
vážné důsledky v případě selhání systému;
v kontextu síťových databází: složitost fyzické implementace, rigidita komunikace mezi datovými prvky, omezení pohodlí při manipulaci s daty;
hierarchické databáze: těžkopádné,složitost fyzické realizace velkých stromových struktur;
relační databáze: chybějící standardní identifikační nástroje pro každou položku.
Ve skutečnosti rozsah použití určuje různé objekty databáze, které tvoří rozdíly v kritériích pro posouzení výhod a nevýhod. Nezáleží na tom, co je v jedné oblasti aplikace velmi důležité. Stejná databáze může způsobit úspěch nebo zkazit celý podnik.
Organizace informací a údajů
Obecně platí, že informace jsou přírodním jevem a údaje jsou oblastí působnosti kompetence algoritmu, programu nebo vývojáře. Často neexistuje žádný zvláštní rozdíl mezi výrazy informace, data a objekty databáze. Formalizace oblasti aplikace je model: skutečný objekt a objekt v tomto objektu. Například společnost a její finanční složka nebo plánování společnosti a výroby. V každé z těchto dvou úkolů se liší nejen údaje, ale také podmínky jejich užívání.
Účetnictví, čas a datum mají stejný význam a nemohou být přeměněny za zvláštních podmínek (datum podání výkazů v dani, datum splatnosti do rozpočtu, datum splácení služeb, plat platů).
Na oddělení plánování a výroby má čas a datum zcela odlišný význam, ale není zde vázán ani na měsíc ani na čtvrtletí, ale má významný rozdíl - datum může být začátek a konec období.
Dokonce i formát reprezentace číselných informací může být důležitý a je ovlivněn vnější okolností. Včera byly peníze měřeny tisíci amiliony, dnes jsou to ruble a penny. Včera bylo zapotřebí dvacet číslic celé části a nula ve zlomku, dnes je pouze pět číslic celé části, ale nutně dvě číslice - ve zlomku. To je zejména, ale ve skutečnosti je spousta.
nezaujaté analýze databází a jejich aplikace pro stanovení Základním kritériem pro správnou tvorbu jejich organizace, skutečně funkční databáze - je informační systém řízení, který odráží jeho dynamický a může se přizpůsobit, aniž by programátor.
Dynamika organizace dat
Existuje rigidní datový model, dokud se vnější okolnosti nezmění. Začátkem devadesátých let nikdo nepomyslel, že dvě číslice v datovém poli, vyčleněném pro rok, stačily. Kolik panice a problém způsobil bariéru 640 KB paměti na úsvitu počítačového budování. Jak hrozné je dnes přístup k datům z dBase, Clarion, FoxPro, zatímco na začátku devadesátých let to bylo všechno v pořádku. Jak vývojáři, tak uživatelé byli šťastní. Ale pak tam bylo málo informací, a algoritmy byly primitivní. Co se stane, pokud je dnes nejméně jedna super databáze mimo provoz? Oracle a další představitelé průmyslu se znalostmi a zodpovědného přístupu k návrhových dat organizace. Není ani jisté tabulky úrovni nebo databáze a real informačních toků a systémů, které odrážejí globální transformaci z širokého spektra úkolů.
V současné době, hierarchická databáze - není jedinou možností relační vztahy s přihlédnutím údaje nerovnost, podřízenost jednohonebo jinou závislost něčeho na události, předmětu nebo jednání spotřebitele. Hierarchie doplňuje relační koncept v tom smyslu, že vymezuje práci na úrovni databáze, tabulky, dotazy a aktuální informace. Hierarchii lze nejen použít v jednoznačném a přirozeném smyslu, ale síťová databáze může existovat ve stejném počítači, aniž by se lišila od funkčnosti a schopností od sebe, která pracuje na stovkách serverů po celém světě.
Příklad: sledování poštovních zásilek
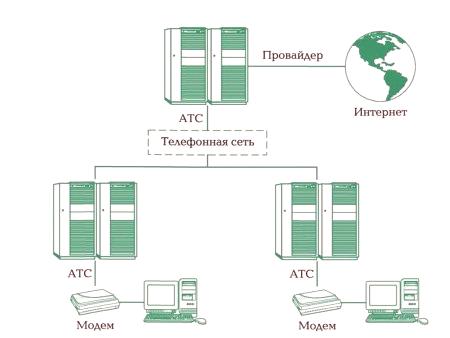
Implementace je síťová databáze. Ale nejen databáze nebo systému a různé země a společnosti, které poskytují službu, shromažďují a zpracovávají informace. Jedná se o hierarchickou databázi na úrovni samostatné společnosti a v každé implementaci bude podobná hierarchie vztahů. Uvnitř země je síťová infrastruktura. V každé konkrétní aplikaci, když návštěvník webového zdroje hledá poštu, funguje celá síťová databáze, která nebyla navržena jako jedna entita, ale byla vytvořena "sama" kvůli rozsahu.
Faktor rozmanitosti implementací a velmi specifická žádost s odpovědí na ni. Podobnost je založena na základních prvcích a funkčnosti, stejně jako existují pouze specifické způsoby, jak poskytovat poštovní zásilky pro zásilku. Existují způsoby dodání a průnik celních orgánů podle jednotlivých zemí. Výsledkem je struktura databáze na zemi. To určuje dostupnost a možnost zavedení "automatického" mechanismu výměny dat. Ale komunikační linky nejsouvždy správně pracovat. Servery mohou být také servisovány.
Lokální mezipaměť distribuovaných informací
Systém sledování pošty nikdy nevyžaduje přístup ke všem informacím najednou. Jedná se o běžný výskyt ve všech oblastech aplikace: existují všechny nahromaděné a přístupné informace, ale existuje malá část, která je relevantní v určitém časovém okamžiku. Nic nebrání tomu, aby webový zdroj vytvořil lokalizovanou metodu distribuované databáze. Například přišel návštěvník. Dokonce ještě předtím, než formuluje požadavek, můžete přidat odpověď. Pokud existují zkušenosti s návštěvníky z určité země, pak může být známo, od kterých zemí se očekává, že obdrží data.
V některých zemích je sledovací systém naložen hlavně s místními dotazy (v rámci země), nic nebrání tomu, aby se tento okamžik optimalizoval, a externí odesílání poskytly jiným webovým zdrojům. V některých případech je nutné nejen poskytnout návštěvníkům externí informace, ale také odpovídat informacím o odezvě na stejný dotaz z různých sledovacích systémů. Řekněme, že v tomto případě bude možné objektově-relační model informace a přístup k němu v jistém smyslu, ale pro implementaci tohoto modelu bude nutné poskytnout modelovací nástroj pro společnosti působící v oblasti dozoru, tj. Rozvíjet jejich vlastní funkčnost.
Systémy pro zpracování distribuovaných informací
Existují pouze dva varianty, u kterých se typy databází mohou výrazně lišit. Vývojář sám staví distribuovaný model zpracování, simuluje procesy,formuluje dialogové algoritmy a provádí všechny sousední akce. Druhá možnost: mnoho vývojářů vykonává svou práci, shromažďuje a poskytuje informace, které vedou k vzniku možnosti využívat distribuované zpracování informací. Pro toto není nutné vytvořit vlastní zdroj. Každý vyhledávač je příkladem správy prostřednictvím přístupových klíčů k distribuovaným datům.
Pokud formulujete správné dotazy, můžete dostat odpovídající odpovědi. Nezáleží na myšlence všech webových zdrojů, vývojářů a vlastníků databází, kteří poskytují informace. Je důležité, aby toto klíčové slovo používalo vyhledávač, jehož kompetence již shromažďuje informace nebo je znovu shromažďována.
Slovo, které vůbec nezáleží
Hlavním problémem v oblasti informací je rychle rostoucí dynamika, na kterou je uživatel nejen zvyklý, tvoří ho sám a má zájem o přiměřenost nástrojů, které používá. Databáze - ne nejdynamičtější a nejdynamičtější nástroj. Ať už to vývojář chce nebo ne, ale je vždy v zajetí technologie. Nemůže vytvořit databázi, která není podporována existujícími DBMS, ale vytvoření vlastní verze v 99% případů není možné a realistické.
Mezitím existuje a částečně implementuje jiný přístup k vytváření moderních informačních systémů. Abstrakce, která s sebou přinesla objektově orientované programování a cloudové technologie, vám umožňuje definovat slovo, které na počátku nezáleží, ale získává to v průběhu času. Každý to dělá sámpodnikání. Databáze pracují v běžném režimu, objevují se nové, staré jsou upgradovány. Webové zdroje přebírají funkce systémů správy databáze na uživatelské úrovni. Vyhledávače spojují klíčová slova a dotazy s dostupným prostorem pro informace shromážděné podle jejich jedinečných kritérií. V těchto dvou příkladech a webových zdrojích - oknech v databázi a vyhledávačích, sestavených podle kritérií informací, představují skutečně fungující myšlenku dynamického využívání informací.
Dynamické databáze
Problém s bezpečností vedl k problému omezení přístupu. Mnoho jmen a hesel, mnoho zaměstnanců a zvýšení počtu ztrát informací, přístupu, osobních údajů. Práce v zájmu práce není nejlepší řešení. Společnost je odhodlána plnit své poslání, nikoli zajistit, aby její bezpečnostní služba podporovala normální práci svých zapomnějících zaměstnanců. Lidský faktor zde je důležité zvážit. Přiměřená a požadovaná odezva dynamických databází, které okamžitě zachycují celou infrastrukturu společnosti a jejích zaměstnanců, automaty poskytované každému podle jeho autority z jakéhokoli zařízení.
Služby technické podpory, předplatitelské služby, telefonní centra - správná reakce kombinuje řadu systémů jízdenek do jediné databáze, nejen hlas a e-mail od zákazníků, ale i události plynoucí z práce společnosti. Charakteristickým rysem moderního zpracování informací: odborníci se naučili pracovat v dynamice a využívat statického potenciálu objemnýchdatabází v podmínkách měnících se potřeb.
Svět objektů, systémů a řešení
Skutečné objekty a platné systémy jsou sjednoceny v oblasti aplikace osobou, která rozhoduje. Samotná skutečnost navštívení zdroje, odkazující na objekt, pomocí systému, má účel a dosažený výsledek. Není třeba fantazovat o umělé inteligenci, když stačí akumulovat praxi rozhodování o osobě a její použití. Není nutné vázat rozhodnutí zaměstnanců jedné společnosti na práci této struktury.
Rozsah antivirové ochrany již dlouho shromažďoval virové hrozby ze všech možných směrů a generalizoval je pro použití v každém případě. Čím vyšší je míra zabavení rostoucích hrozeb, tím účinnější je boj s nimi na konkrétních pracovištích. Když je informační systém schopen shromažďovat rozhodovací zkušenosti, je to dobrý start a osvědčení o způsobilosti vývojářů, záruka stability spotřebitelského rozvoje a celkový úspěch.