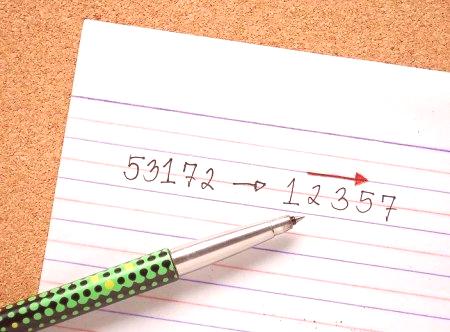Informace měly vždy přiměřený dynamický zájem. Vývoj programovacích jazyků relačních databází a informačních technologií radikálně změnil obsah a strukturu zájmu. Existoval určitý přísný systém zastoupení. Formalizace, přesná matematika a binární vztahy se staly úspěšnou a rychle se rozvíjející oblastí znalostí a zkušeností. Přirozený svět informací nezměnil dynamiku a vývoj obsahu a struktury se zvýšil na novou výšku. Má hladký tvar, který v přírodě není nic "obdélníkového". Informace samozřejmě podléhají formalizaci, ale mají dynamiku, nejen data a algoritmy jejich změny v procesu zpracování, samotné úkoly a jejich aplikační oblasti se mění.
Informace & gt; formalizace dat
Informace jsou přeměněny na data (datový model, informační struktura databáze), jak ji programátor vidí. Neexistuje žádná záruka, že tato vize je správná, ale pokud její program řeší úkol, pak byly údaje pravděpodobně správně prezentovány. Otázka, jak dobře byly formalizované informace - je otázkou času. Zatím se koncept dynamiky (přizpůsobení se měnícím se podmínkám užívání) - jen sen o programování. Funkční závislost: "správné řešení = program (programátor)" a podmínka: "trvalá shoda" platí ve většině případů, ale pouze společně. Ale to není matematický základ, který se používá při vytváření databází.
Příméprohlášení: přirozená a kontinuální dynamika informací a algoritmů pro řešení problémů vždy. Relační databáze jsou binární vztahy + přísná matematika + přesné formální konstrukce, +
Data, soubory a databáze
Jak jsou data uložena, je již dlouho bezvýznamná: zda je to RAM nebo externí zařízení. Hardwarová součást dosahuje stálého tempa vývoje a zajišťuje dobrou kvalitu ve velkých objemech. Hlavní možnosti ukládání se liší v možnostech využití dat:
soubory; databáze.První je věnována programátorovi (zaznamenávat, v jakém formátu, jak to udělat, jak číst), druhý okamžitě přináší potřebu znalosti o jednoduché funkční závislosti. Rychlost odebírání a zaznamenávání informací při práci se soubory (rozumná velikost, nikoli astronomická) je velmi rychlá a rychlost podobných operací s databází může být někdy výrazně pomalá.
Osobní zkušenosti a kolektivní mysl
V dějinách byly učiněny pokusy dosáhnout hranic, ale relační databáze jsou stále dominantní. Kumulovaný velký teoretický potenciál, praxe aplikace je rozsáhlá a vývojáři - vysoce kvalifikovaní. Pojem funkční závislost vývojářů databází uložený programátorovi, i když nemá v úmyslu používat bohaté matematické a logické zkušenosti s budováním složitých informačních struktur, procesy práce s nimi, odběr vzorků a zaznamenávání informací. I v nejjednodušším případě programátor závisí na logice databáze, kterou si zvolil.Neexistuje žádná touha řídit se předpisy, můžete použít soubory, získat mnoho souborů a mnoho osobních zkušeností. Bude to trvat hodně osobního času a úkol bude vyřešen na dlouhou dobu.
Bez ohledu na to, jak komplikované se mohou zdát příklady funkční závislosti, není nutné se ponořit do hlubin významu a logiky. Často je třeba připustit, že kolektivní mysl dokázala vytvořit vynikající databáze s různou velikostí a funkčností:
solidní Oracle; vyžadující MS SQL Server; je populární MySQL.- vynikající relační databáze s dobrou pověstí, snadno použitelné a rychle se rozvíjející telefony. Jejich aplikace šetří čas a eliminuje potřebu psát alternativní listy pomocného kódu.
Programování funkcí a dat
Programovací již dlouho nemoc vždy něco kopírovat, opakujte předchůdce práce, něco, aby se přizpůsobily novým informačním, úkoly nebo podmínky použití. Funkcí funkční závislosti je, že stejně jako v programování může být chyba velmi nákladná. Úloha je zřídka snadná. Obvykle se při formalizaci informací objeví výsledná složitá prezentace dat. Obvykle jsou přiděleny jejich prvky, pak jsou v určitých vztazích propojeny klíči, pak jsou vytvořeny algoritmy pro tvorbu tabulek, požadavků, algoritmů pro odběr vzorků. Šifrování je často velmi důležité. Ne všechny databáze nabízejí mobilní řešení a často se můžete vyrovnat s tím, jak dobře je MySQL vyladěnoExistují desítky databází, které dokonale a stabilně pracují, a vynucují vývojáře, aby vytvořil jedenáctý základ podobný tomu, který již existuje. Existují případy, kdy obecný hosting omezuje funkčnost PHP a to způsobuje mrtvici při programování přístupu do databáze. V moderním programování je odpovědnost za programový algoritmus ekvivalentní odpovědnosti za vytvoření datového modelu. Všechno by mělo fungovat, ale nemělo by se vždy ponořit do bahna teorie.

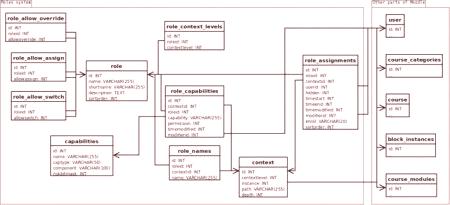
DB: jednoduchý vztah údaje
Za prvé, koncept databáze - databáze a systém pro správu databází (například MySQL), a určité informační architektura, která odráží vaše cíle a komunikace mezi nimi . Jedna MySQL databáze "drží" sama sebe, kolik chcete informační struktury v různých oblastech aplikace. Jedna základna Oracle, může poskytnout informace zpracovává velké společnosti či banky pro řízení bezpečnosti a údaje na nejvyšší úrovni, která se nachází na sadu počítačů, které jsou v různých vzdálenostech, různé nářadí prostředích.
Předpokládáme, že vztah je základem relačního modelu. Jednoduchý vztah je množina sloupců s názvy a řádky s hodnotami. Klasický "obdélník" (tabulka) je jednoduchým a efektivním dosažením pokroku. Složitost a funkční závislost databáze začíná, když se "obdélníky" začnou vzájemně propojovat. Název každého sloupce v každé tabulce by měl být jedinečný v kontextu úkolu. Jeden a ten samý nemůže být ve dvoutabulky Poznat význam pojmů:
"určovat podstatu"; "odstranění nadbytečnosti"; "opravit vztah"; "k zajištění jistoty".je základní potřebou pro použití databáze a vytvoření datového modelu pro konkrétní úkol. Porušování každý z těchto pojmů - algoritmus neefektivní, pomalé vzorkování, ztráty dat a další problémy.
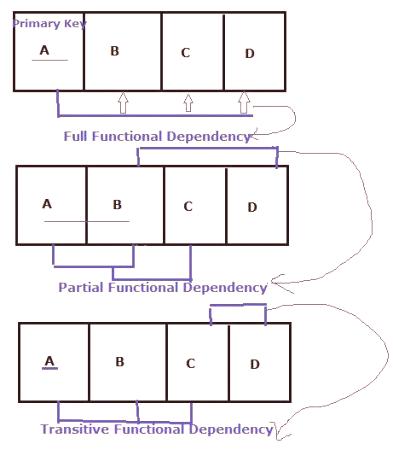
funkční závislost: logika a význam
Nelze přečíst o tic vztahů, které fungují - odpovídající sadu argumentů nastavení hodnot a funkcí - není jen vzorec nebo plán, ale může být vzhledem k tomu, mnozí hodnoty - tabulka. Ne nutně, ale to není na škodu reprezentovat vztah: F (x1 x2, xN) = (y1 y2, yn). Ale je třeba si uvědomit, že u vchodu - stůl, výstupní tabulky nebo příliš konkrétní řešení. Obvykle logika funkční vztah vytváří vztahy mezi tabulkami, dotazy, výsady, triggery, uložené procedury a další body (složek) databáze. Obvykle jsou tabulky převedeny jeden na jeden, pak do výsledku. Použití funkční závislosti se však neomezuje pouze na takovou myšlenku. Programátor sám staví svůj model dat domény vidění obrazu, informace o struktuře nezáleží na tom, jak volat, ale jestli to funguje v určité databázi, musí být založeno na jeho logice, za její obsah a dialektem použitého jazyka, jako pravidlo, SQL . Lze tvrdit, že vlastnosti funkčníhoZávislosti databází jsou k dispozici prostřednictvím dialektu jazyka SQL. Ale mnohem důležitější pochopit: po všech těch Potíže ne tolik databází přežil, ale mnoho dialektů jazykových prvků a vnitřních struktur v databázích taky.
na staré dobré Excel
Když se počítač ukázal se na druhou stranu, svět kdysi rozdělen na programátory a uživatelů. Typicky je první použití:
PHP, Perl, JavaScript, C ++, Delphi. MySQL, Oracle, MS SQL Server, Visual FoxPro.Druhý:
Slovo.Excel.Někteří uživatelé dělat umudryayut samostatně (bez pomoci programátorů) v databázi Word - skutečný nesmysl. Zkušenosti uživatelů v aplikaci Excel pro vytváření databází jsou praktické a zajímavé. Důležité je, že samotný Excel je funkční, barevný a praktický. Tabulková idea definoval pojem funkční závislost jasné a přístupné, ale nuance jsou v každé databázi. V každém z jeho "tváří", ale všechny Excel do Oracle manipulovat jednoduché čtverce, to je, tabulky. Vzhledem k tomu, že Excel - to není databáze, ale mnoho nick (nikoliv programátoři), je to tak zvyklí, a Oracle - je komplexní a výkonný dosažení velké skupiny vývojářů je v databázi, se stává přirozenou přiznat - databáze je idea konkrétního programátora (týmu) o konkrétním úkolu a jeho řešení. Co je to funkční závislost na tom, kde, proč, samozřejmě, jen autor nebo tým.
o tom, kam jít relační vztah
vědecký a technický pokrok - velmi bolestivý proces, a někdy i krutý. Pokud si pamatujeteTo, co začalo s databází, která je * .dbf, značkové jako kybernetika, počítačové vědy a lásky pak začal organizovat pohyb high-tech bariéry na úrovni jednotlivých zemí, je zřejmé, proč je relační databáze tak houževnatý a dobře. Proč klasický styl programování k tomuto dni života, a objektově orientované programování prostě ocení, ale ne ovládnout. Bez ohledu na to, jak moc by byla funkční závislost v kontextu matematiky:

Toto není binární vztah, spíše se jedná o příležitost přehodnotit myšlenku založit vztahy mezi více atributů zkoumat komunikace „jeden k mnoha“, „mnoho k jednomu“, „mnoho k mnoho“ nebo „Kolik vůbec ale zejména“ . Varianty vztahů mohou přijít hodně. Toto je matematika s logikou a je přísná! Informace jsou vaše vlastní matematika, zvláštní. V tom mohou být formality řečeny pouze s velmi velkým mínusem. Můžete formalizovat práci personálního oddělení, psát ACS pro těžbu ropy nebo produkci mléka, chleba, provést výběr v obrovské základně Google, Yandex nebo Rambler, ale výsledek je vždy statická a pokaždé to samé! V případě, že funkční závislost = přísné logiky a matematiky = základ pro databázi, dynamika, která může mluvit. Každé rozhodnutí bude formálně jakékoliv formální datový model + = jasná algoritmus přesné a jednoznačné rozhodnutí. Informace a oblasti aplikací se vždy mění. Vyhledávací nástroj, který se provádí na stejné vyhledávací fráze, nemůže být jeden a tentýž čas za hodinu nebo dva,jedinečně jeden den - v případě, že vyhledávání fráze se vztahuje na informace, které se počet míst, zdrojů, znalostí a dalších prvků neustále mění.
Na tratích a předměty
I v případě, že program je čistě matematická a její databáze není ani přemýšlet o dynamice všechno tam je vždy čára. A řádky jsou dlouhé. A nemůže být nekonečná. Nemůže být ani proměnná, podmíněně proměnná. Mimo jiné jakékoliv databáze jejich matematické a binární-byrokracie ukládá hodně formality, u kterých rychlost + vzorkování kvality a zpracování. Pokud některé položky v počtu databází, bude především materiál, který omezení, která zní: čísla bitu, přítomnost písmene „e“, formát prezentace - zkrátka všude a vždy mají důležité vlastnosti funkční databáze závislosti: linie podmíněně s proměnnou délkou s hmotností binární formalit a přísnými matematickými omezeními. Chcete-li změnit tón a poslouchat dynamiky pulsní, vše lze natírat předměty. V prvním přiblížení název sloupce v tabulce - seznamu objekt jmen - na stejném zařízení, menší stůl - Objekt čepic a to názvy záhlaví sloupce. A hlavičky nemusí být vůbec Ale v tabulce mohou být řádky. A linka může mít hodnotu. A proč by měly být vždy stejné číslo. Úplný čtvercový stůl je nehoda a ve většině případů soukromá.

Je-li přítomny všechny struktury v objektu databáze, pak se snad není nutné vybudovat striktní binární vztahy. To je přirozené a skutečnécož znamená alespoň proto, že je založeno na objektivní (jednoznačně nematicové) logice, která odráží dynamiku informací a prostředí, ve kterém jsou úkoly.