Pokud sémantická organizace informací zjistila, že se skutečně uskutečnila, pak by se rozsah jednoznačného návrhu MySQL okamžitě stal sebezničujícím. Moderní databáze jsou postaveny v relačním vztahu mezi daty, takže úloha odstranění duplicitních záznamů je relevantní.
Vznik identických řetězců obvykle není problém, který nelze vyřešit, avšak zabránění duplicitě obsahu tabulkových polí je v mnoha případech prakticky nerealistické.
Organizace databáze
"Správná" databáze se pokládá za obsahující unikátní tabulky a každá obsahuje jedinečná pole. Je povoleno mít stejný obsah v polích různých tabulek, pouze pokud jsou klíčové a logická komunikace je prováděna.
Tabulka personálu například přejde do tabulky údajů o zaměstnancích pro konkrétní pole. Personální tabulka obsahuje pouze to, o čem odkazuje v konkrétním podnikovém kontextu, a seznam zaměstnanců obsahuje pouze osobní údaje pro zaměstnance. S touto verzí budou MySQL odlišné údaje pracovat na požadavku na obě tabulky, která spojuje personální zajištění se zaměstnanci.
Jedinečnost tabulek a polí
Při vzájemném ovlivňování tabulky personálu a seznamu zaměstnanců pro každý řádek první tabulky je zvláštní místo ve druhém. Druhá tabulka může obsahovat stejné příjmení, jména, patronymické osoby, adresy města mohou obsahovat stejné ulice. PokojeDomy a byty nemusejí mít zvláštní význam (nevyužívají mnoho prostoru).
V ideálním případě jsou všechna totožná slova umístěna v různých tabulkách a odpovídají jim jedinečný klíč. Například seznam všech ulic, příjmení, jména, patronymic. V tabulce personálu se původní schémata spojí do požadované možnosti odeslání a tabulka zaměstnanců neobsahuje seznam zaměstnanců, ale žádost o ně a ty, které jsou s ním spojeny.
Více systematické informace, tím důležitější je použití MySQL odlišné. Pro správnou organizaci dat musejí platit - při kombinaci tabulek se celkový počet řádků vzorku zvyšuje úměrně počtu řádků v každé tabulce. Jedná se o abstraktní příklad, obvykle vývojář neupřesňuje informace v takovém rozsahu. Použití funkce MySQL distinct řeší tento problém: vyberte požadované položky. Může existovat analýza odstavců o větách, větách a frázových frázích. V tomto případě, bez slovníku nemůže dělat, ale bude muset udělat glosáře konjugace, konce a další prvky syntaxe jazyka.
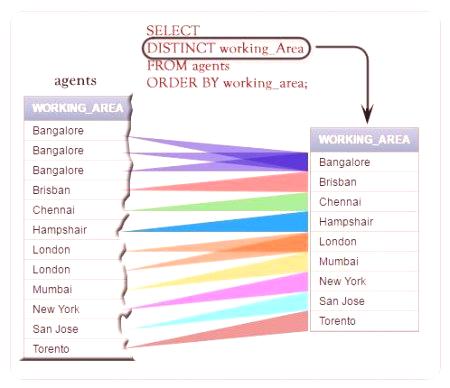
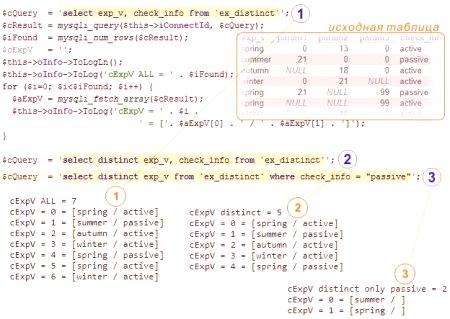
Vzorek dotazu MySQL "vyberte zřetelný" dotaz
Tabulka obsahuje záznam, ve kterém jsou čtyři období a dva stavy záznamu: aktivní a pasivní. Vzorky vzorků:
všechny záznamy;
pouze unikátní;
jsou v podmínkách jedinečné.
Mohou být uvedeny v obrázku v článku.
Funkce operátora výběru pouze jedinečných záznamů vyhovuje jakýmkoli datovým strukturám. Můžete použít dotaz v souboružádat, seskupit a třídit data před výběrem. Je však vždy nejlepší co nejvíce zjednodušit práci s databází. Použití MySQL odlišné v jednom poli je vždy lepší než to dělat hned.
Je zvláště důležité pečlivě sestavovat dotazy, které kombinují více tabulek. Jakékoli sloučení dat v relačních databázích před operací konstrukce kde a join má za následek velké objemy dat. Orientace v nich vyžaduje pozornost a přesnost od developera.